实验室工作
Report this week (5.30 — 6.5)
Inverse kinematicsto control Piper going up and down;- Try to reproduce
GraspNet-1B.
使用 IK 控制 Piper 机械臂的运动
Use curobo project, needs the urdf and usd of Piper
Python 代码示例 (IK/FK 控制 Piper 机械臂)
1 | |
安装 GraspNet 环境
pythonneeds 3.8, the only one which can compile drivers successfully, butopen3derrors (needglibc 2.18)- Compile
open3dby source code ot install byconda(conda cannot do this)?(needclangbut I do not haveSUDO) python3.7, cannot compile other cuda drivers.
Report this week (6.6 – 6.12)
Curobo in server
- load pytorch by
pip,condagetsglibcerror, - need to run
pip install scikit_build_coreafter load pytorch, module load cuda/12.1 gcc/9.3.0beforepip install -e . --no-build-isolation- 暂时无法解决
Configure Curobo of Piper
- urdf and usd,
- use Lula Robot to create sphere,
- some configure need to change,
- current result:

- possible result: FK different from hands and gripper.
Report this week (6.26 – 7.3)
- reproduce Minimind-V and understand the code of Vision-Language model;
VLM model
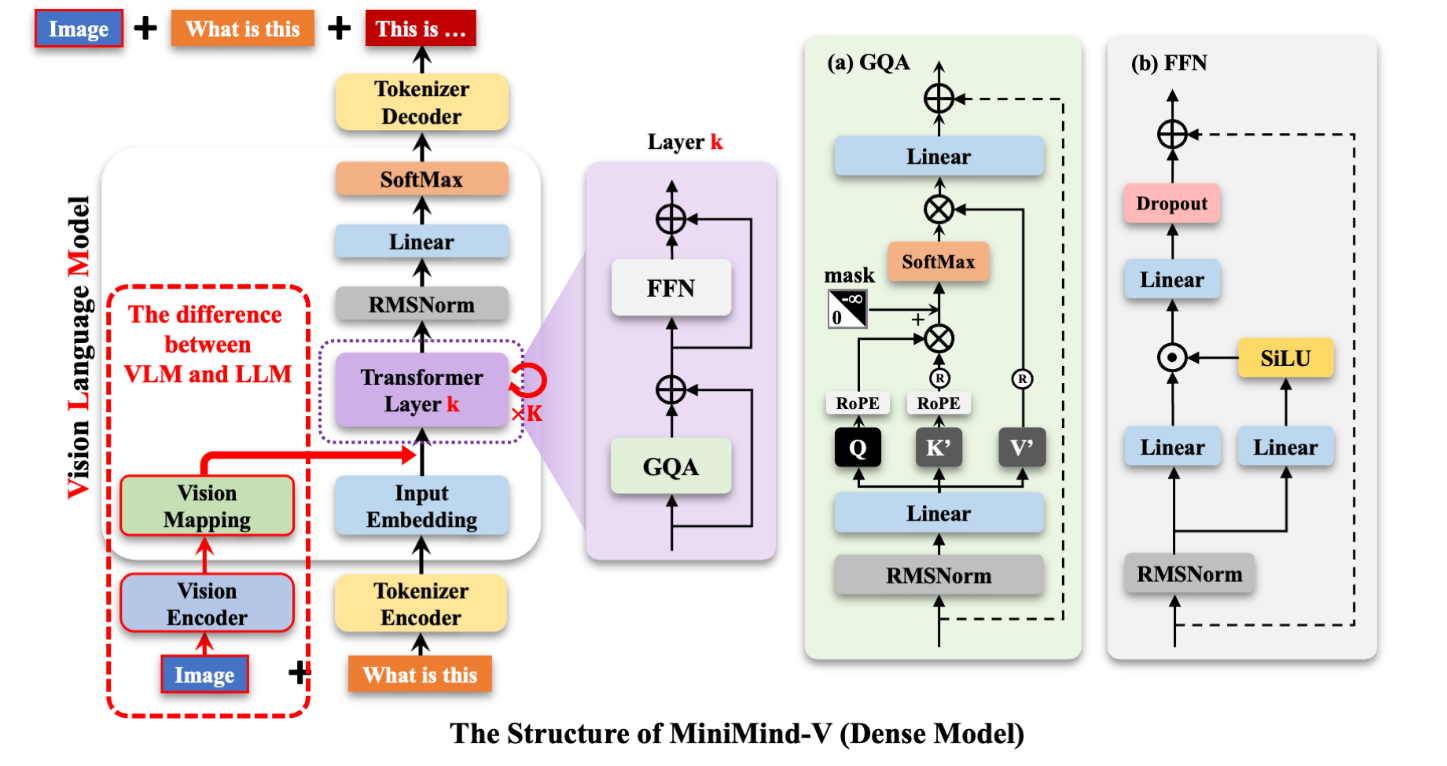
Assume that the batch size is , seqence length is , hidden size is , vocab size is .
- Input example: “<image>\n这个图像中有什么内容?”
- Prompt: “\n这个图像中有什么内容?”, input_ids: “ … … ”
- To tokens:
- Image feature:
- Replace the position of to image feature, so the input shape of transformer layers is
- Output shape of transformer(after RMSNorm) is also
- Output shape after the linear classification layer is
VLA model
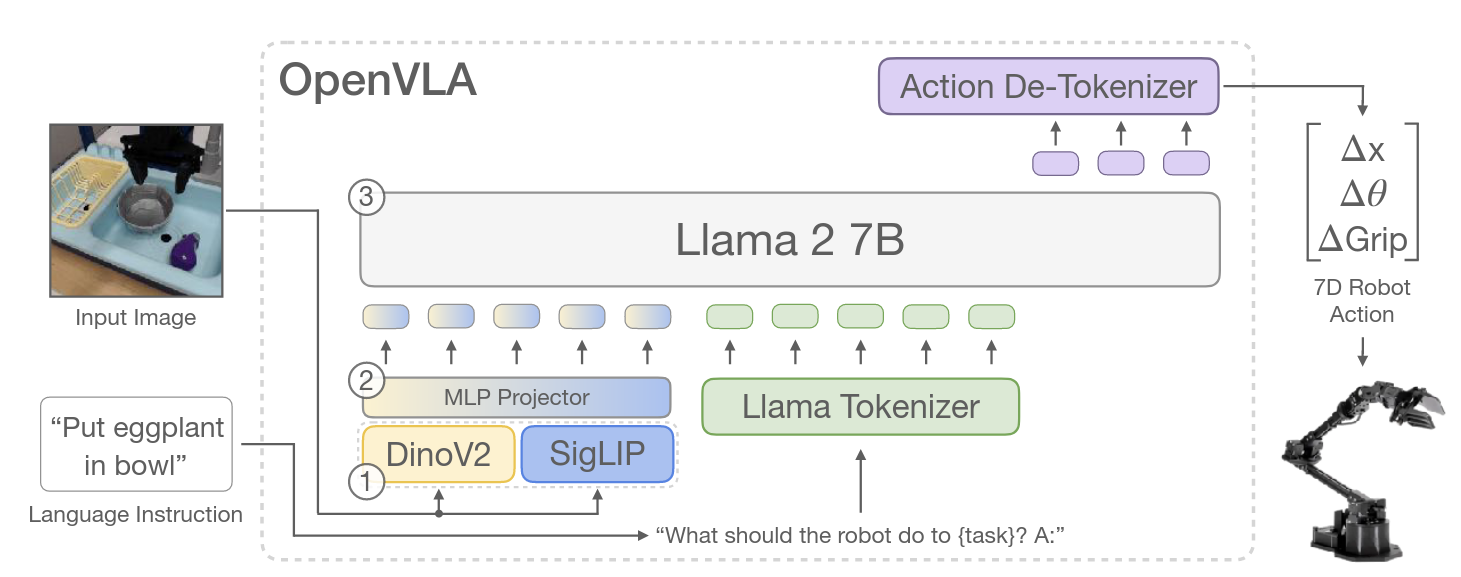
Use the structure of OpenVLA, the last token ids are action tokens.
- Input example: “<image>\n机器人应该怎么做才能完成{任务}?答:”
For OpenVLA, image features are always placed at the beginning of the prompt. - Input_ids: “ … … ”
- To tokens:
- …
- Output shape after the linear classification layer is , and assume the last tokens are “ ”
- This last tokens would be decoded into action ranged , that is
Formula:
VLM to VLA
- Training mode: freeze vision model and train language model;
- Training data: , or common dataset, first using libero data?
- Model Architecture: requires implementing an action tokenizer and model architecture needs fine-tuning: for example, the image’s position must always be at the very beginning of the prompt.
- Inference Code: using the Libero simulation environment.
VLM Pretrained Result
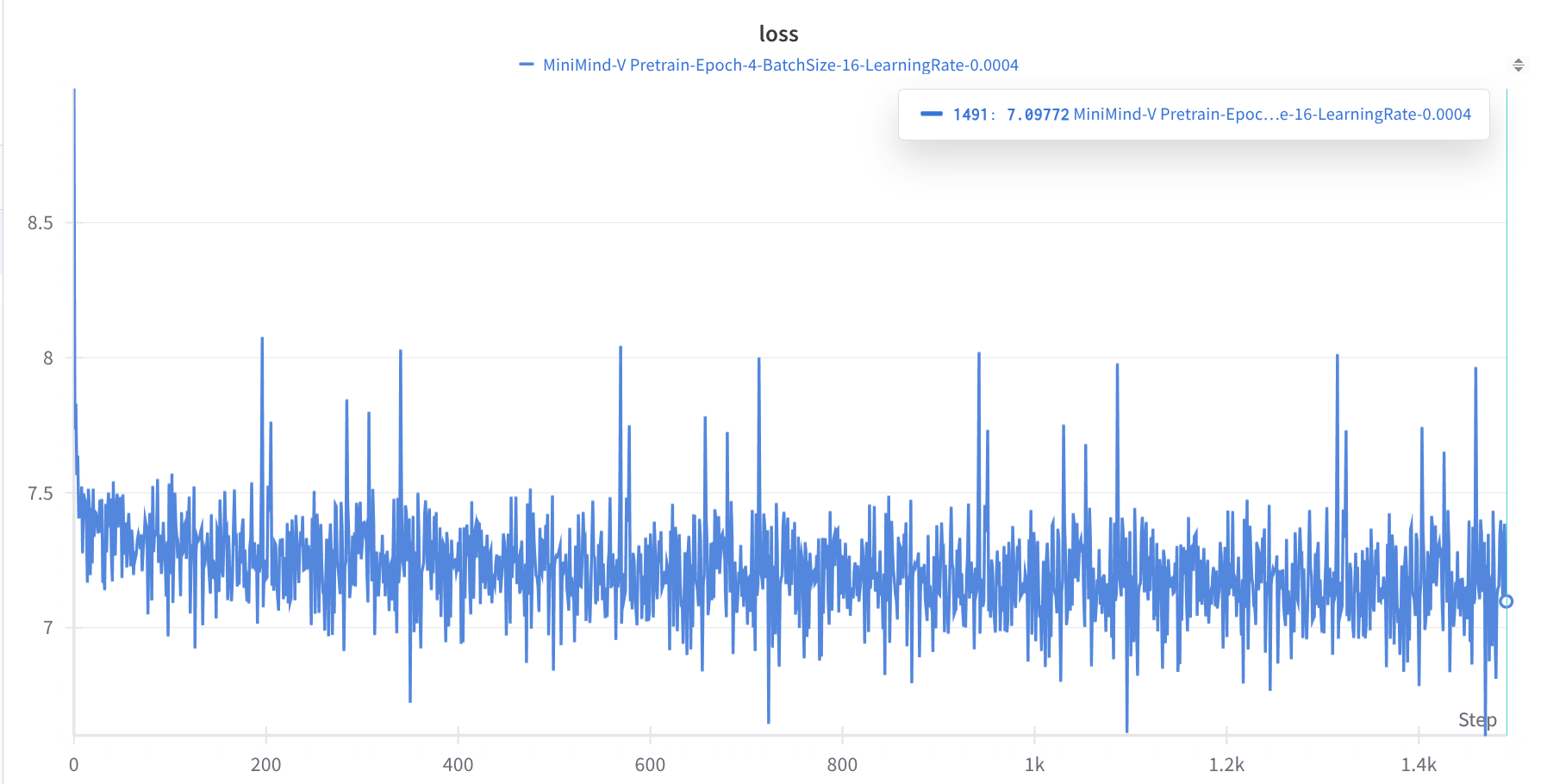
The pretrained model has not been evaluated yet, given the huge loss gap compared to what author reported, I suspect there’s an issue with loading the pre-trained language model.
Next week
- Complete the VLA structure and training script;
- turning LIBERO dataset to RLDS or Lerobot or common dataset;
- 训练时的输入架构?查看openvla
- 直接通过训好的 vlm 进行训练
Report this week (7.3 – 7.10)
OpenVLA架构研究与实现:深入分析了OpenVLA的输入架构,并着手实现了类似的结构。Action Token筛选:从 个词汇中,筛选出使用频率最低的 个token序号,并整理生成了action_token_map.json文件。Libero数据集处理:成功下载了Libero数据集,并将其处理成模型训练所需的格式。
Work
1. OpenVLA Input Structure
-
输入与输出形状 (Input/Output Shape):
输入/输出部分 维度/形状 (Dimension/Shape) <bos>(起始符)[bs, 1, hidden_size]image features(图像特征)[bs, num * 196, hidden_size]text features(文本特征)[bs, text_length, hidden_size]action tokens(动作指令)[bs, 7, hidden_size]<eos>(结束符)[bs, 1, hidden_size] -
时间错位机制 (Temporal Misalignment):
- 模型输入 (Input):
- 模型输出 (Output):
-
损失计算 (Loss Calculation) 策略:
- 官方策略:同时计算
text features和action tokens的损失。 - 备选策略:仅计算
action tokens的损失。
- 官方策略:同时计算
-
后续优化点:
- 根据原论文,当前实现缺少本体感知特征和历史信息特征,可在后续版本中迭代添加。
2. Least Used Tokens
-
发现问题:与
Llama不同,minimind的词汇表并非按使用频率倒序排列。例如,词汇表的最后5个是常见英文词:"Ġeconomy": 6395"Ġethically": 6396"éĻĪ": 6397"Ġschools": 6398"Ġnetworks": 6399
-
解决方案:为精确找到真正低频的
token以用作action token,我下载了约 13G 的中英文语料数据集,并使用minimind的tokenizer对其进行词频统计,筛选出频率最低的词汇,并将其索引存入action_token_map.json文件。
3. Libero Dataset
-
数据加载:直接利用 Hugging Face 提供的
lerobot格式Libero数据集,简化了数据获取流程。1
2from datasets import load_dataset
ds = load_dataset("physical-intelligence/libero")['train'] -
数据适配:对数据集进行了格式处理,当前阶段主要使用
ds['image'](主视角图像),ds['wrist_image'](腕部图像) 和ds['action'](动作)。任务描述则通过json文件加载。 -
LiberoDataset类代码预览:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27class LiberoDataset(Dataset):
def __init__(self, hf_dataset, transform=None, task_file_path='dataset/meta/tasks.jsonl'):
self.dataset = hf_dataset
self.transform = transform
# 加载任务信息
self.task_info = load_task_info(task_file_path)
def __len__(self):
return len(self.dataset)
def __getitem__(self, idx):
sample = self.dataset[idx]
image = self.transform(sample['image'])
wrist_image = self.transform(sample['wrist_image'])
state = torch.tensor(sample['state'], dtype=torch.float32)
actions = torch.tensor(sample['actions'], dtype=torch.float32)
task_index = sample['task_index']
# 根据 task_index 获取任务描述
task_description = self.task_info.get(task_index, f"Unknown task {task_index}")
return {
'image': image,
'wrist_image': wrist_image,
'state': state,
'actions': actions,
'task_description': task_description,
}
Problems
- 模型格式问题:发现
minimind-v预训练模型似乎没有可用的.pth格式权重。加载官方提供的.pth文件会导致输出乱码,只有Hugging Face格式的model.bin则可以正常使用。这是否意味着我们还是需要再进行预训练? - 语言能力限制:当前模型主要处理中文,这是否会对
VLA(Vision-Language-Action) 模型的性能,产生负面影响?
Report this week (7.10 – 7.17)
- 成功让训练代码跑起来,但是结果还没有进行验证,也就是并没有训练到底,有可能训练代码存在问题;
- 全量微调正好需要吃掉24G显存
- 下周先训练一下这个模型,并且查看一下代码是否有问题,写一下 evaluation 的脚本
- 感觉可以在训练时给长任务分配大一点权重。
Report this week (7.17 – 7.24)
- 训练代码中增加动作正确率检测环节;
- 写好Libero的evaluation代码,但是还没有检查细节;
- 对数据集的处理进行了一些改动;
Training Scripts
训练代码中增加动作检测环节:
1 | |
目前动作输出正确率如下,不知道结果是否正常。
| 训练轮数 | 训练集Loss | 测试集Loss | 训练集动作准确率 | 测试集动作准确率 |
|---|---|---|---|---|
| 1 | ||||
| 2 | 0.6424 | 0.8550 | 0.1272 | 0.1165 |
| 3 | 0.5552 | 0.9446 | 0.1001 | 0.1016 |
| 4 | 0.4880 | 1.0350 | 0.0862 | 0.0949 |
| 5 | 0.4332 | 1.1186 | 0.0785 | 0.0793 |
LIBERO Evaluation
这个代码已经写好,现在正在检查细节是否有问题,预计下周可以测试一下训练出来的模型是否有效果。
Dataset
- 对main image 和wrist image使用不同的归一化代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17self.stats = load_stats(self.stats_path)
self.main_tfs = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=self.stats['image']['mean'], # [0.485, 0.456, 0.406]
std=self.stats['image']['std'] # [0.229, 0.224, 0.225]
)
])
self.wrist_tfs = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
mean=self.stats['wrist_image']['mean'], # [0.512, 0.398, 0.321]
std=self.stats['wrist_image']['std'] # [0.201, 0.189, 0.243]
)
]) - 由于我认为动作准确率不高,所以对action数据,根据openvla论文中说的,首先收集好了每个动作维度的1st和99th中位数,将其放入stats.json中,接下来以它们为min action和max action,这样就可以减少异常动作的影响。(这个因为有7维动作,似乎需要7个min和max,但openvla中好像没有这个考虑,具体代码我还在实现中。)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32def compute_and_save_action_quantiles(self, quantiles=[1, 99]):
"""
计算动作数据的分位数并保存到stats.json文件
quantiles: 要计算的分位数列表,例如 [1, 99]
stats_path: stats.json文件路径
"""
stats_path = self.stats_path
total_samples = len(self.dataset)
all_actions = []
for i in tqdm(range(total_samples), desc="Loading actions"):
sample = self.dataset[i]
actions = np.array(sample['actions'])
all_actions.append(actions)
all_actions = np.array(all_actions)
print(f"Action data shape: {all_actions.shape}")
# 计算每个维度的分位数
action_quantiles = {}
for q in quantiles:
action_quantiles[f'{q}th_percentile'] = np.percentile(all_actions, q, axis=0).tolist()
# 读取现有的stats.json
with open(stats_path, 'r', encoding='utf-8') as f:
stats_data = json.load(f)
# 更新actions部分
if 'actions' not in stats_data: stats_data['actions'] = {}
stats_data['actions'].update(action_quantiles)
with open(stats_path, 'w', encoding='utf-8') as f:
json.dump(stats_data, f, indent=4, ensure_ascii=False)
Problems
我觉得可以增加一些框架,对state进行处理。
Report this week (7.25 – 7.31)
- 给ActionTokenizer每个维度加上1st - 99th 分位数;
- 完成大部分的推理代码撰写,但是还没有调试通KV cache的部分;
- 完成ddp加速训练代码的撰写。
- 完成对action-only的loss计算。
1st Percentile
实现方式是把分位数提取出来放进config中,然后在解码的时候,根据不同的动作维度进行解码。
1 | |
DDP
- 初始化:获得当前rank(0为主进程),所有的print信息只在主进程上打印
- 数据集需要并行处理:用DistributedSampler
1
2
3
4train_sampler = DistributedSampler(train_dataset, num_replicas=world_size, rank=rank)
val_sampler = DistributedSampler(val_dataset, num_replicas=world_size, rank=rank, shuffle=False)
sampler.set_epoch(epoch) # 保证每个epoch数据打乱的方式不同 - 模型需要封装:保存模型时,需要保存model.module.state_dict()。
1
model = DDP(model, device_ids=[local_rank], find_unused_parameters=True)1
torch.save(model.module.state_dict(), checkpoint_path)
Action Only Loss
思路:在输出的结果中,找到那些是action_token 的输出位置,并将其设置为计算loss。
1 | |
发现有问题。希望的修改方式:严格按照格式,mask掉除了7个action以外的任何位置。
Evaluate
其他部分已经全部调试好,目前只剩下model输出时候的函数predict_action还没有完全实现,主要难点在如何实现kv cache上。
- kv cache: 即只在在没有缓存(即首次调用)时,才进行图像特征的提取和拼接;在有缓存时,则跳过这些操作,因为其所需要的信息都储存在past_key_value中。
- 动作token选择:找到概率最高的动作token,然后输出。
本周工作报告 (2025年7月31日 - 8月7日)
本周主要围绕模型的推理与评估展开,具体工作总结如下:
- 实现并验证了
predict_action函数:完成了该函数在使用与不使用 KV Cache 两种模式下的代码编写,并通过实验成功验证了其功能。 - 运行评估(Evaluation)流程:成功跑通了完整的评估代码,但在过程中发现模型评估结果存在明显问题。
- 问题定位与调试:当前工作的重心是深入分析并定位评估准确率为零的原因。
Predict Action 函数详解
此函数是模型推理的核心部分,其功能是根据给定的起始符 <bos> 和图像信息,自回归地生成7个 action dim 数值,这7个值共同构成了机械臂要执行的动作指令。在模型的词汇表中,动作由256个特定的 Token 表示,因此在生成的每一步,我们都选择概率最高(greedy search)的 Token 作为输出。
KV Cache 是一种通过复用先前已计算 Token 的键(Key)和值(Value)信息,来加速后续 Token 生成的技术。这是一种以空间换取时间的经典优化策略。从下面的推理时间对比可以看出,KV Cache 显著降低了模型的推理延迟。


评估代码
评估代码现已能顺利运行。其核心依赖于 predict_action 函数的正确实现,该部分的完成是打通整个评估流程的关键。
当前遇到的问题
在运行评估流程后,发现所有任务的成功率均为0。通过回放任务视频,观察到机械臂在每个步骤都执行完全相同的动作(持续向右移动)。
为定位问题,我进行了代码调试,发现模型在每次推理时,无论输入如何变化,都输出完全相同的动作指令序列(Action Tokens)。如下图所示,调试信息确认了这一异常现象。目前,我正在深入排查导致此问题的根本原因。

// …existing code…
本周工作报告(2025年8月14日 - 8月21日)
本周由于入职上海人工智能实验室实习以及服务器集群资源紧张,实验进展相对有限。主要工作集中在论文阅读、问题诊断和后续计划制定上。
Paper reading
GAMMA:Graspability-Aware Mobile MAnipulation
Key word: Grasp, Mobile, Fusion
Debug
通过 ipdb 对模型输出进行深入调试,发现了一个关键问题:
- 训练阶段:模型能够输出多样化的动作token
- 评估阶段:在剔除语言token后,模型总是产生相同的动作token序列
Prob
基于调试结果,提出以下两个可能的原因:
- 推理函数缺陷:训练过程正常,但
generate函数的实现存在错误 - 训练阶段假象:训练时观察到的动作多样性可能是由于未剔除language token导致
Future Work
-
损失函数优化:给loss增加一个非动作惩罚项,并绘制对应的 loss 曲线。
-
评估机制完善:增加调试信息,在evaluation的时候,输入两张图片,看看他输出的结果和目标结果是否一样
多个相同输入输出,看eval时能不能输出对应的值。
本周工作报告(2025年8月12日 - 8月28日)
- 深入排查了训练与验证代码,定位并修复了一处关键Bug,使得模型目前能够生成语义正确且有效的动作指令;
- 集成了Weights & Biases (W&B) 工具,用于实时监控并记录训练过程中的各项关键指标;
- 对项目整体代码进行了一次大规模重构,显著优化了代码结构,提升了可读性与可维护性。
Bug Find
-
首先,为排查模型是否在训练初期就无法生成动作Token,编写了
detect_action函数进行检测。实验表明,此问题并非根本原因:在首个Epoch训练仅20秒后,模型输出已全部为有效的动作Token。

-
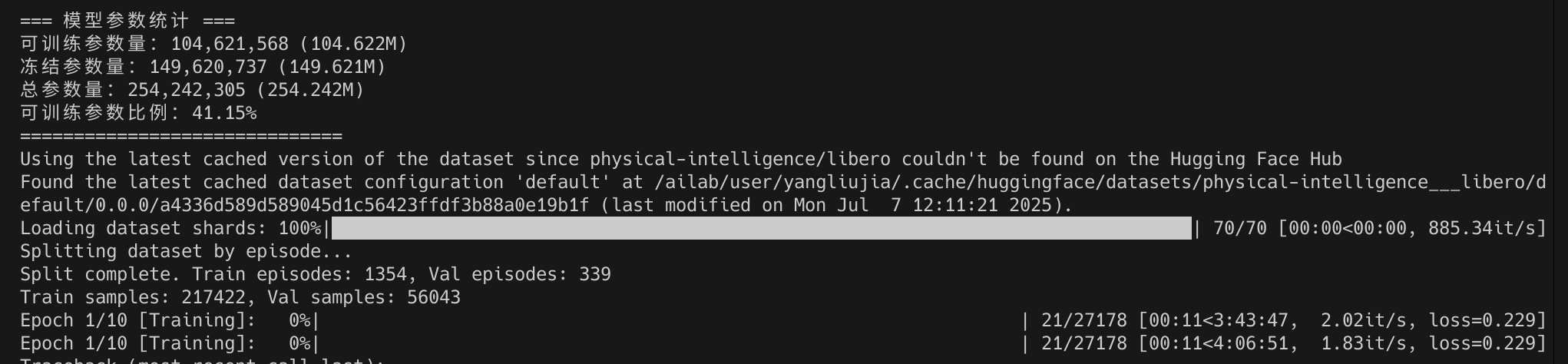
其次,对模型的损失(Loss)曲线进行了分析。下图展示了使用4块GPU并行训练20个Epochs后的结果:
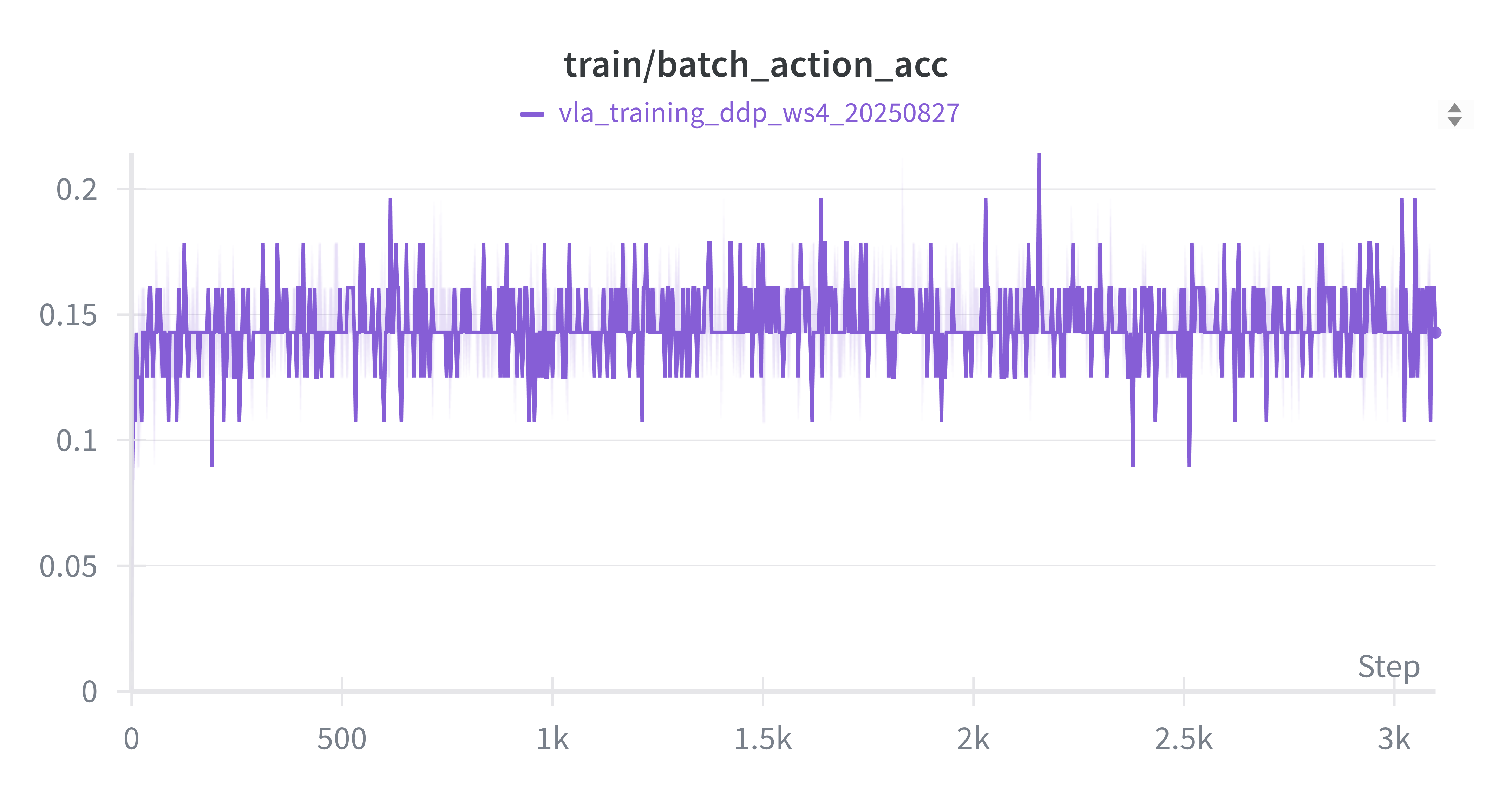
从图中可以看出,各项指标曲线的整体趋势符合预期,但在第8个Epoch后模型开始出现显著的过拟合现象。后续实验也证实,严重过拟合的模型在评估任务中表现不佳。训练集 Loss (Batch) 训练集动作准确率 (Batch) 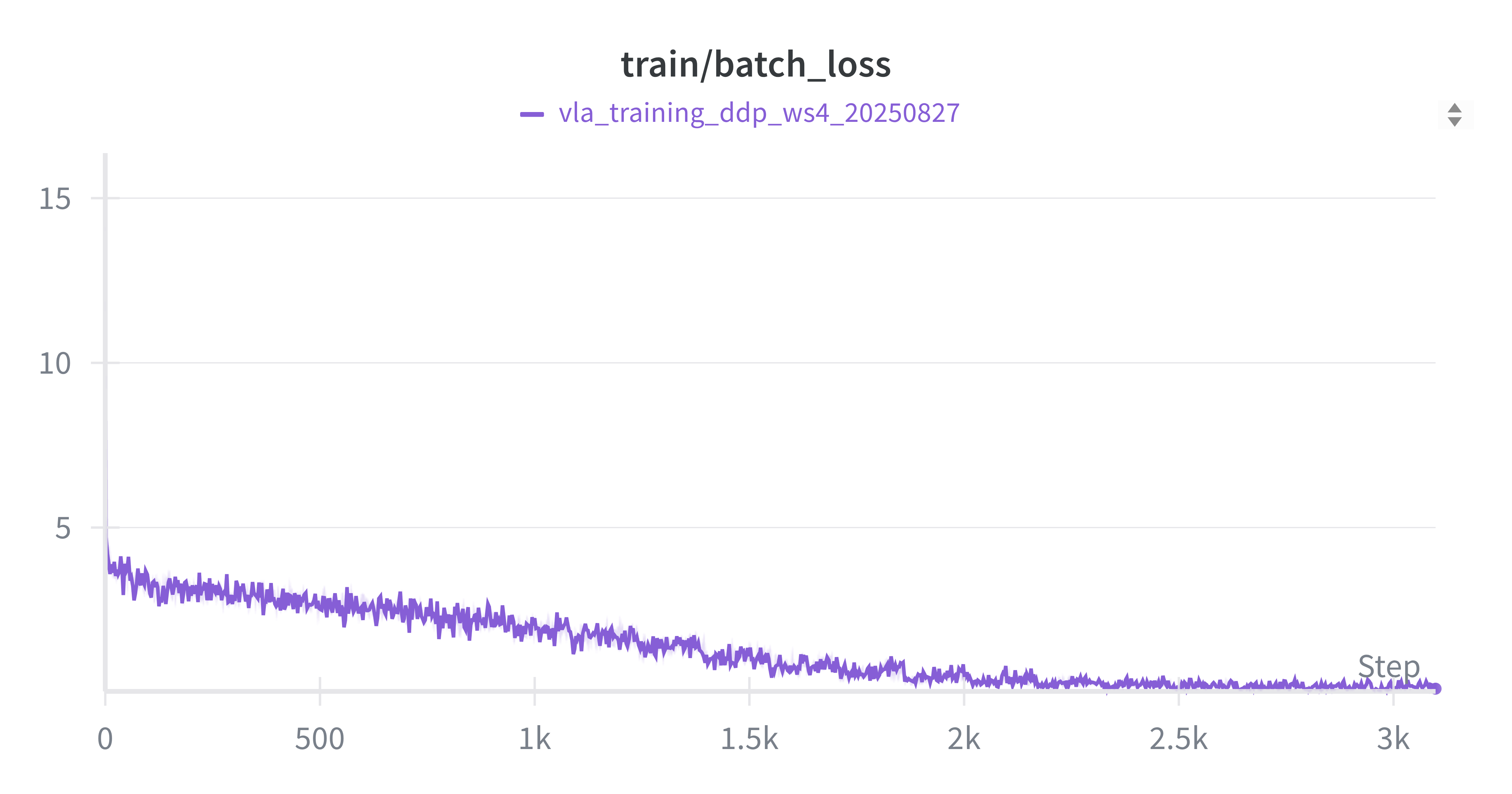
验证集 Loss (Epoch) 验证集动作准确率 (Epoch) 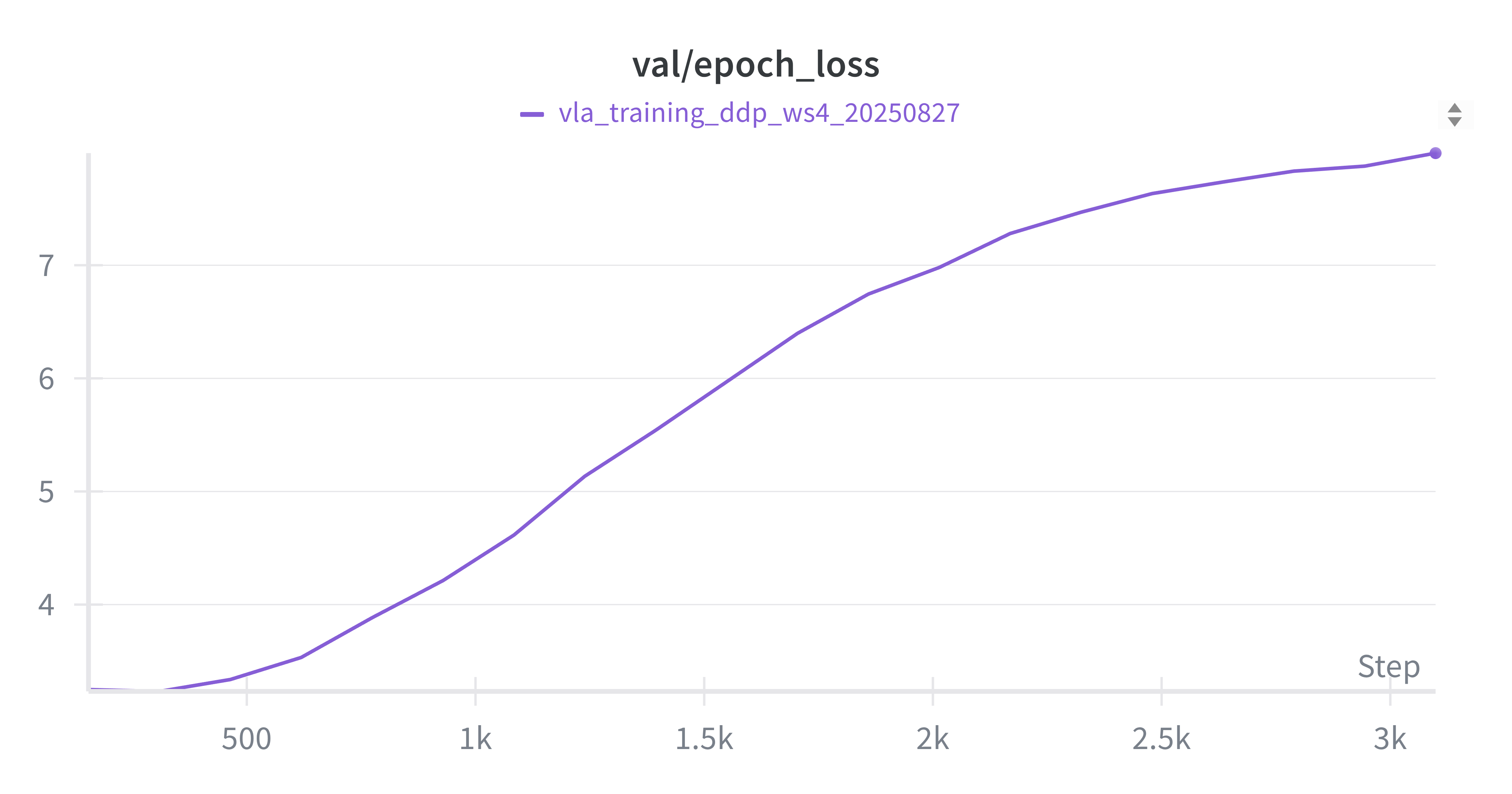
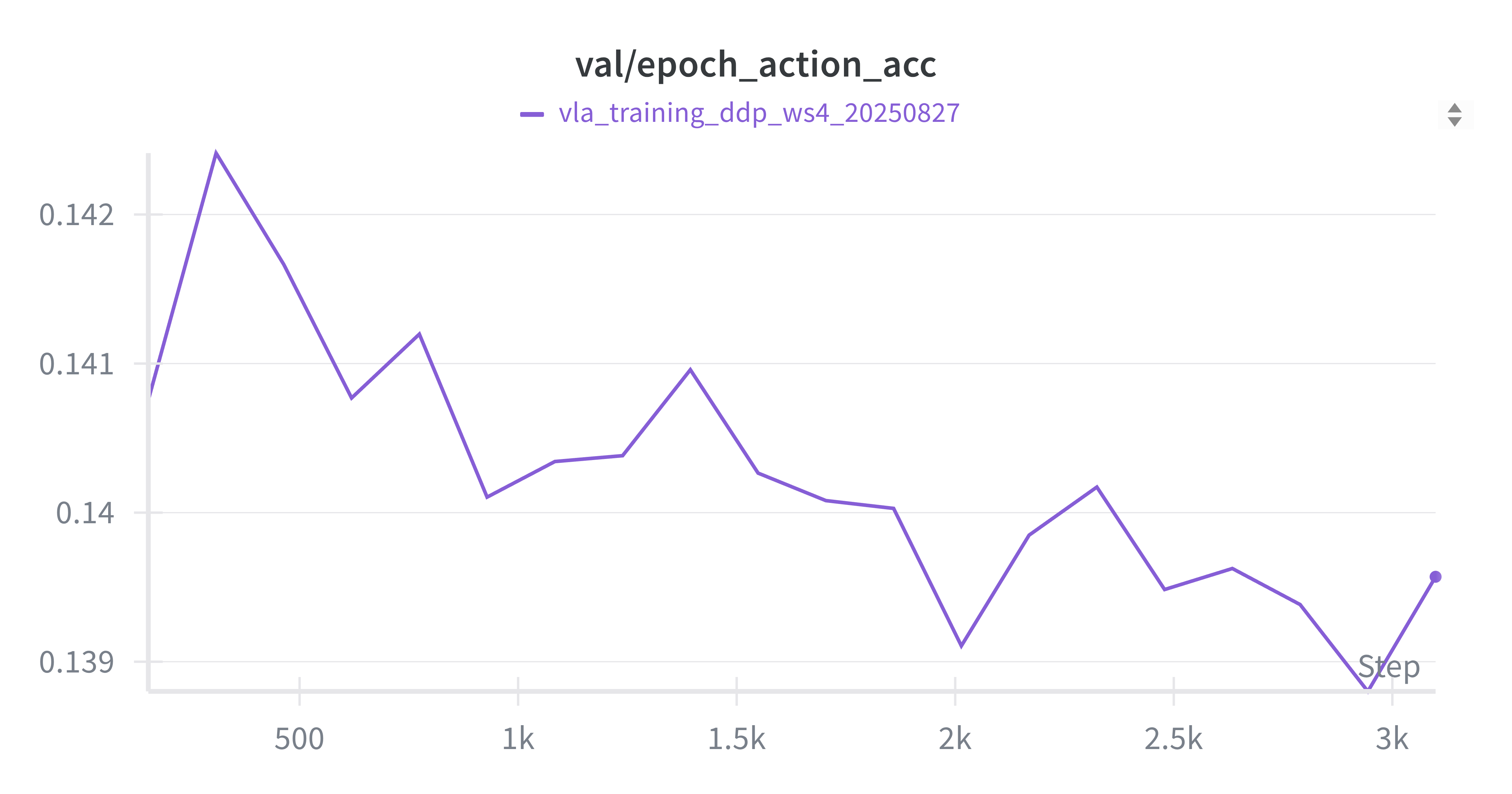
-
最后,通过对评估(Evaluation)代码的逐行审查,定位了问题的根源:
- 训练阶段:由于Libero数据集提供的图像尺寸为(256, 256),而CLIP模型要求输入为(224, 224),因此数据预处理流程中包含了对图像的缩放(Resize)和归一化操作;
- 验证阶段:直接从Libero仿真环境中获取了(224, 224)尺寸的图像,无需进行缩放操作,导致了训练与推理之间的数据处理不一致(Data Gap),这是导致评估失败的核心原因。
- 在修复问题后,我对单个轨迹进行了评估,不同训练阶段(Epoch)的模型表现如下: 实验发现,自第9个Epoch起,模型便无法成功完成任务,这与先前观察到的过拟合现象相吻合。
Epoch 1 Epoch 2 Epoch 3 Epoch 4 Epoch 8 Epoch 9
Beautify project code
- 为提升代码的可维护性和模块化程度,原先冗长的
train_vla_ddp.py脚本被拆分为多个独立模块,新的项目结构如下:
1 | |
Next Week
- 完善eval.py脚本,对所有任务进行全面的成功率评估;
- 调研并尝试新的模型结构,如smol-VLA中采用的Diffusion模型;
- 在更多样的数据集上测试当前模型的泛化能力。
本周工作报告(2025年8月28日 - 2025年9月4日)
- 完善eval.py脚本,对所有任务进行全面的成功率评估
- 为模型的图片输入增加数据增强模块,以抑制过拟合现象
- 为模型添加state信息输入功能
Data Augumentation
对输入的主相机和手腕相机图像进行随机裁剪、亮度变化,并最终完成归一化处理
1 | |
训练完成后,从损失函数对比图可以看出,过拟合现象得到了明显缓解
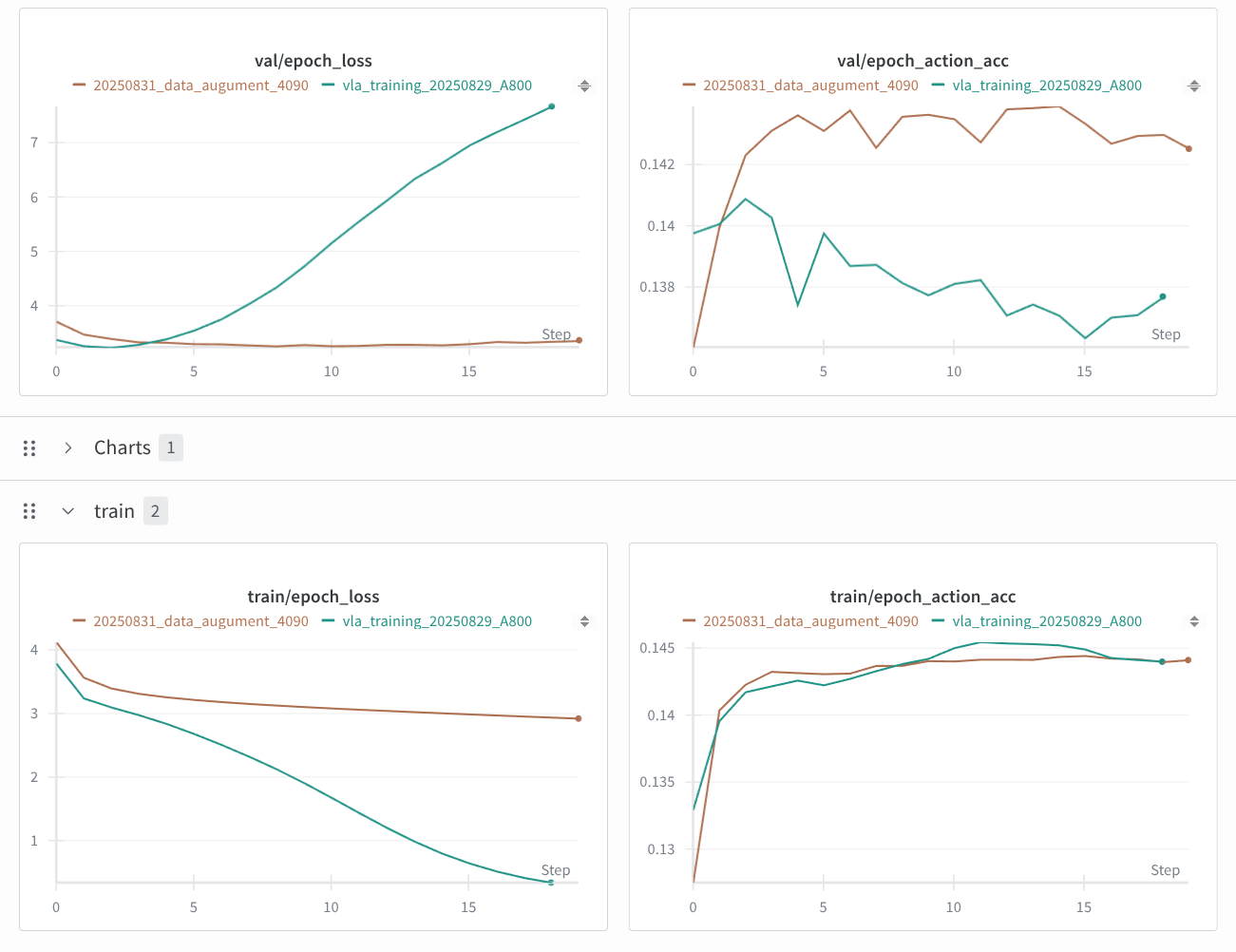
State Input
为了提升模型性能,将机械臂的关节角度以及夹爪信息同样输入到模型中。 将这8维状态信息进行归一化处理后,通过MLP投影到与token相同的隐藏层维度,作为1个token进行输入。
Problem
- 怀疑数据集的state数据存在问题:观察发现大部分数据的最后两维数值相反,推测应该是夹爪的开合信息;但franka机械臂除夹爪外应有7个自由度,而最终state仅有8维,似乎franka的最后一个自由度被忽略了
- 在引入数据增强后,虽然模型的损失曲线表现正常,但模型却只学会了输出一种动作——保持静止不动!


第一张图片显示,所有输出的token id都是各自维度中最接近0值的那个
可能原因:数据增强参数设置过于激进
看pi0源码