Robosuite 论文阅读
RoboSuite 论文 地址
Introduction
robosuite 由 MuJoCo 引擎驱动,主要作用是通过物理仿真模拟机械臂与环境交互,提供一系列的 API,可以从中获取数据进行数据驱动的强化学习和模拟学习。
最新版本:1.5,支持 7 种 机器人(robot),8 种抓取臂(gripper),6 种控制模式和 9 种标准任务。
系统模块
-
模型 API:用模块或程序去定义、描述仿真环境,可生成仿真模型(Simulation Model),也叫环境(environment)。环境通过传感器来生成监控结果(如相机生成画面),并从策略(policy)或 I/O 接收动作指令,这些指令由控制器(controller)将原始动作空间(如关节速度、三维位置等)转化为力矩(torque)而得到。
-
仿真 API:为策略(policy)的输入提供接口,并接收监控结果和奖励(reward)。
-
仿真模型(Simulation Model):由 Task 对象定义,概括了仿真三个重要模块:
- RobotModel():从给定的 XML 文件中加载机器人的模型和对应的夹爪模型(GripperModel);
- ObjectModel():由 MujocoObject 类定义,可从 3D 对象资产种加载,也可以用 API 程序化的生成;
- Arena():定义了机器人的工作空间,包括环境固定装置,如桌面,以及它们的放置位置。
Task 对象通过 MJCF 模型语言,将上面三个组成部分整合为一个 XML 对象,而这个生成的 XML 对象通过 mujoco-py 库传递给 MuJoCo 引擎,进而实例化和初始化仿真模型。实例化后的结果是 MjSim 对象,可通过 API 来访问。
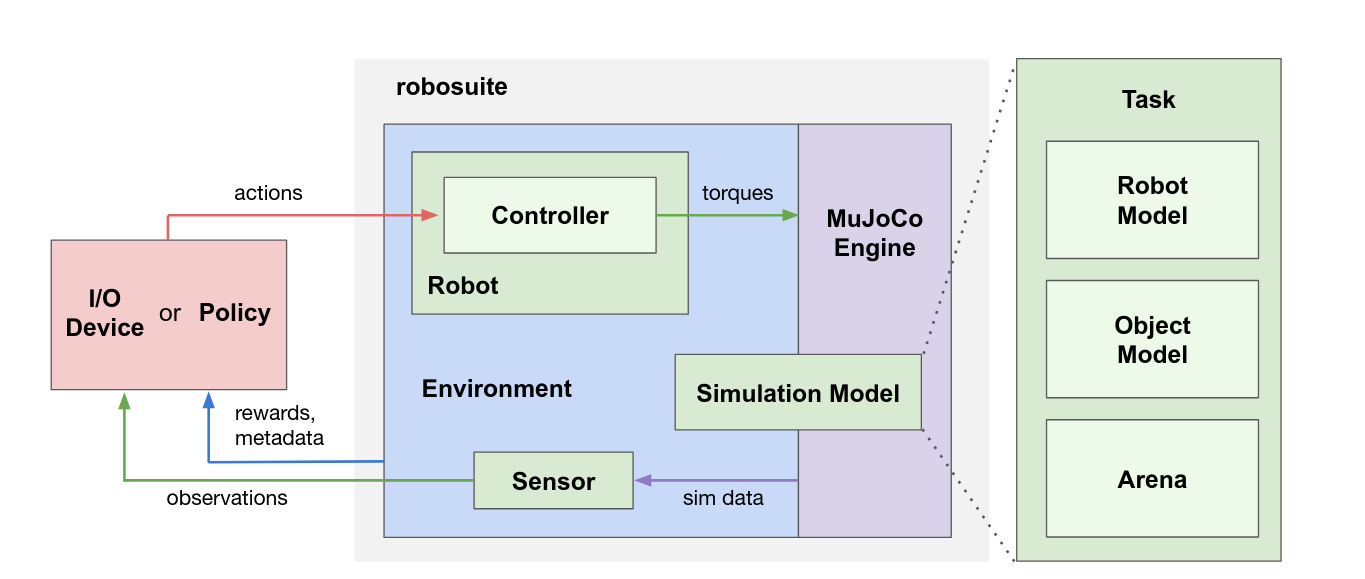
Environment 对象提供了外部输入的 API 接口,可以与仿真交互。外部输入与控制机器人和夹爪的动作命令相匹配,而动作空间与机器人的控制器(controller)相匹配。例如,对机械臂的关节位置控制器,动作空间对应于各关节的期望位置;对于操作空间控制器,动作空间对应于末端执行器期望的3D笛卡尔位置或期望的全6D笛卡尔位姿(X,Y,Z,Roll,Pitch,Yaw)。这些空间指令可以由算法自动生成,或者是通过 I/O 输入。
Sensor 从 MjSim 对象中获取信息并生成监控结果。例如:RGB-D 相机,力-力矩测量计,本体感觉数据,任务进展,成功条件(reward等等)。
Environment
创造环境的代码:make
1 | |
Task 实例包含一个 Arena 模型(基于 XML,定义工作区和相机位置),Robot(arm 种类,如Sawyer, Panda) 和 Object 模型实例(对应物理模型,如立方体、带把手的罐子)列表,还有 placement_initializer 作为输入,决定仿真的开始状态分布。
Robots
Robot 类由 RobotModel, GripperModel(s) 和 Controller(s) 定义,具有以下特点:
- robot 模型多样化、真实化;
- 模块化保障,可以即插即用,可以使用任意机器人、夹爪、控制器组合;
- 自我封闭,任何信息都可在实例中找到。
| 机器人名称 | 自由度 | 夹爪类型 | 描述 |
|---|---|---|---|
| Sawyer | 7 | RethinkGripper | Rethink Robotics 单臂机器人 |
| Panda | 7 | PandaGripper | Franka Emika 协作机器人 |
| IIWA | 7 | Robotiq140Gripper | KUKA 轻型机器人 |
| Jaco | 7 | JacoThreeFingerGripper | Kinova 轻型机械臂 |
| Kinova3 | 7 | Robotiq85Gripper | Kinova 第三代机械臂 |
| UR5e | 6 | Robotiq85Gripper | Universal Robots 协作机器人 |
| Baxter | 7 | RethinkGripper | Rethink Robotics 双臂机器人 |
Controllers
Controllers 将高层的动作转化为底层的虚拟电机指令,驱动机器人运动。
可选项:OSC POSE, OSC POSITION, JOINT POSITION, JOINT VELOCITY, JOINT TORQUE
| Controller Name and Options | Controller Type | Action Dimensions (Gripper Not Included) | Action Format |
|---|---|---|---|
| OSC POSE impedance_mode= fixed | Operational Space Control (Position & Orientation) | 6 | |
| OSC POSE impedance_mode= variable_kp | Operational Space Control with variable stiffness (critically damped) | 12 | |
| OSC_POSE impedance_mode= variable | Operational Space Control with variable impedance | 18 | |
| OSC_POSITION impedance_mode= fixed | Operational Space Control (Position only) | 3 | |
| OSC_POSITION impedance_mode= variable_kp | Operational Space Control with variable stiffness (critically damped) | 9 | |
| OSC POSITION impedance_mode= variable | Operational Space Control with variable impedance | 15 | |
| IK POSE | Inverse Kinematics Control (Position & Orientation) | 7 | |
| JOINT_POSITION impedance_mode= fixed | Joint Position Control | n | n joint positions |
| JOINT_POSITION impedance_mode= variable_kp | Joint Position Control with variable stiffness (critically damped) | 2n | n joint positions and for each joint |
| JOINT_POSITION impedance_mode= variable | Joint Position Control with variable impedance | 3n | n joint positions and for each joint |
| JOINT_VELOCITY | Joint Velocity Control | n | n joint velocities |
| JOINT_TORQUE | Joint Torque Control | n | n joint torques |
git submodule update --init --recursive
Objects
由 MujocoObject 类定义,通过 MJCF XML 格式定义。这些 XML 文件可以保存在磁盘中并加载进仿真模型中,即 MujocoXMLObject;也可以通过代码创建,即 MujocoGeneratedObject。
例:HammerObject,代码见 robosuite/robosuite/models/objects/composite/hammer.py
Sensors
传感器可以测量:图像,力-力矩测量值,压力信号(机械手臂上)等等。除了相机和关节传感器之外,可通过 get_sensor_measurement(sensor_name) 来访问。
每个机器人的关节传感器提供了位置和速度信息,关节传感器可作为 Robot 的 API 的属性进行访问,如 _joint_positions 和 _joint_velocities。
相机并不能直接被查询,在创建环境时指定一个或多个要使用的相机,图像会自动生成并追加到字典中。
Robomimic 论文 地址
从人类数据集离线学习的挑战
- 数据来源于非马尔克夫决策过程。人在操作过程中会有外部因素(以前的经验、操作的设备)等等,而且已经验证过带有时间维度的模型从人类数据集中学习效果很好。
- 不同人的演示存在质量差异(策略、熟练度)。
- 受数据集大小影响。
- 训练与验证目标不匹配。因为从模型中选出最好的模型是困难的。(?为什么)
- 对超参数选择极为敏感。
研究的设计
任务
Lift, Can, Square(Only sim), Transport(Only sim), Tool hang
数据收集
- Machine-generated(MG):针对于 Lift 和 Can 任务,通过最先进的 RL 算法生成的数据(最优和次优),因为其他的任务无法被 RL 算法解决。
- Proficient-Human (PH) and Multi-Human (MH):通过 RoboTurk 平台的人类操作收集,MH 表示为 6 个人的混合数据集(两个熟练的人,两个次熟练的人和两个不够熟练的人)。
- Observation Modalities:设置了不同种类的传感器,包括末端执行器、夹爪手指、关节、gt物体状态、每只机械臂从外部摄像头和腕带摄像头采集的图像。我们有两个观测空间"低维"和"图像"。两者都包括末端执行器位姿和夹持器手指位置,仅在是否使用地面真实物体信息(低维)或该信息是否被可用的相机观测值(图像)所替代方面存在差异。
训练和测试方案
| 算法名称 | 类型 | 主要特点 | 适用场景 |
|---|---|---|---|
| Behavioral Cloning (BC) | 监督学习 | 直接模仿专家演示数据,将状态映射到动作 | 简单任务,数据质量高 |
| BC-RNN | 监督学习 + RNN | 考虑时序信息,能够处理非马尔可夫决策过程 | 需要历史信息的任务 |
| Hierarchical BC (HBC) | 分层监督学习 | 将任务分解为高层目标和低层动作 | 复杂的多阶段任务 |
| Batch-Constrained Q-Learning (BCQ) | 离线强化学习 | 通过限制动作选择来避免外推错误 | 有限的离线数据集 |
| Conservative Q-Learning (CQL) | 离线强化学习 | 保守估计Q值以避免过度估计 | 安全性要求高的场景 |
| IRIS | 模仿学习 | 结合了BC和强化学习的优点 | 需要在模仿和优化间平衡 |
“low-dim”:训练 2000 轮,100 个梯度过程,50 轮验证一次;
“image”:训练 600 轮,500 个梯度过程,20 轮验证一次。
实验
PH 数据集和 MH 数据集
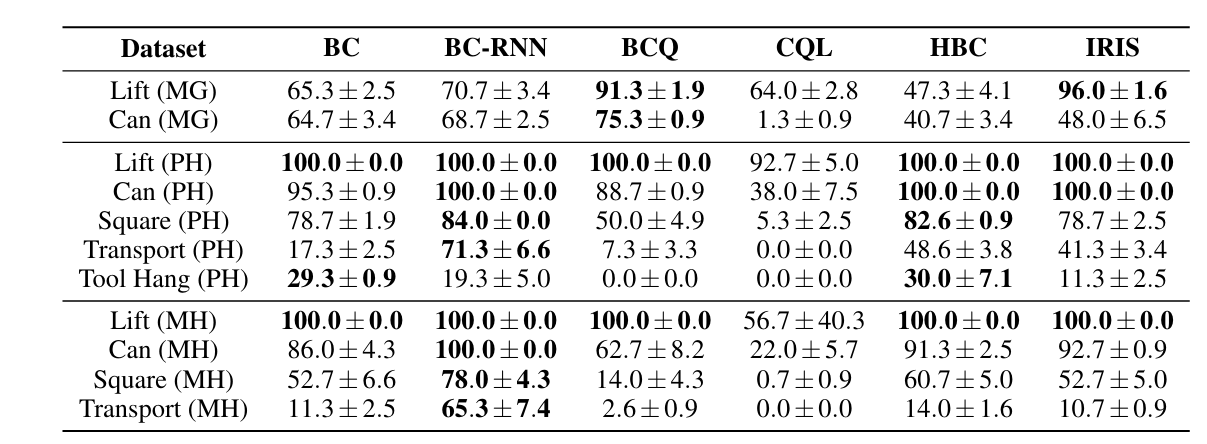
结论:
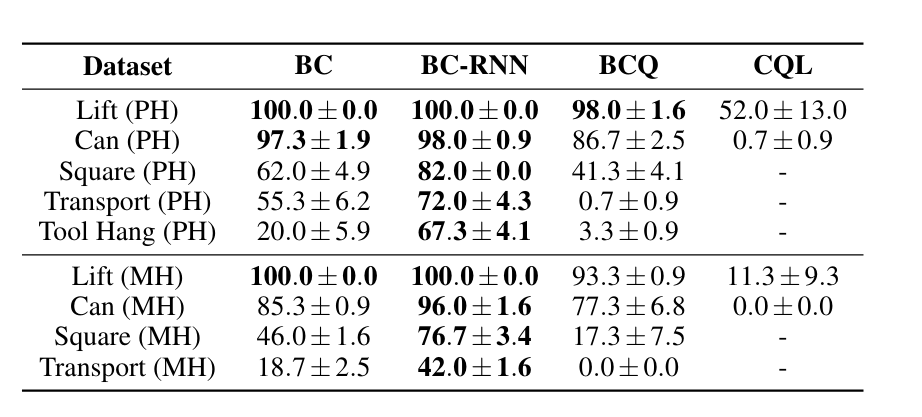
- 有历史记录功能的模型(BC-RNN)比 BC 表现要好。模型在 PH 数据集上的表现好于 MH 数据集,可能是因为 MH 数据集中存在演示质量较差的数据。
- Batch RL 算法(BCQ, CQL)无法从人类数据集中学到东西。
不同质量的数据
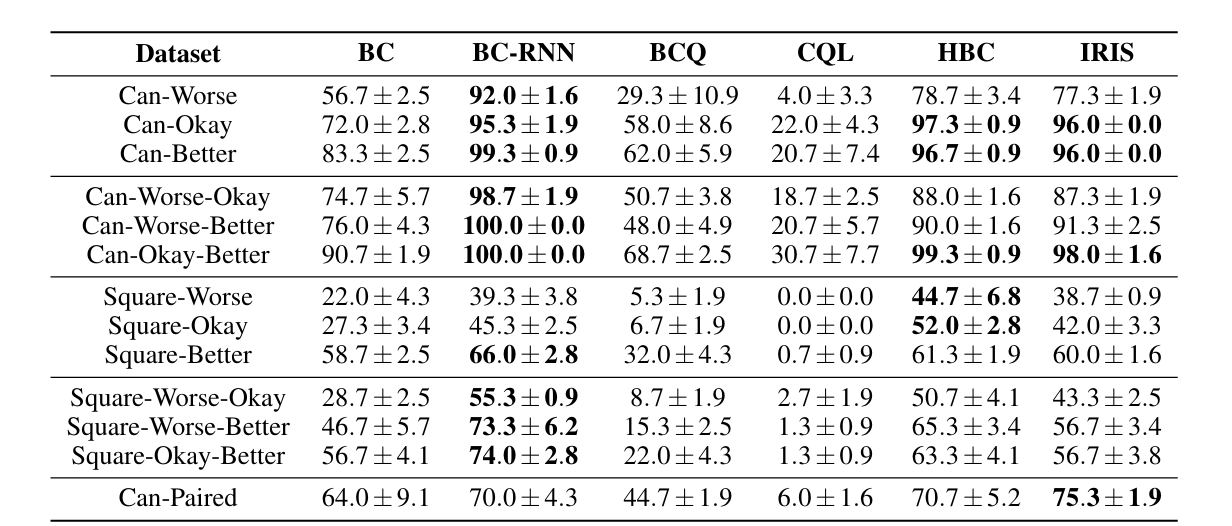
结论:
- BC-RNN 在不同质量的数据集中是一个强 baseline,但是它仍然有提升空间。
- Batch RL 算法在更简单的数据集上也一筹莫展。
low_dim 变为 image 模式
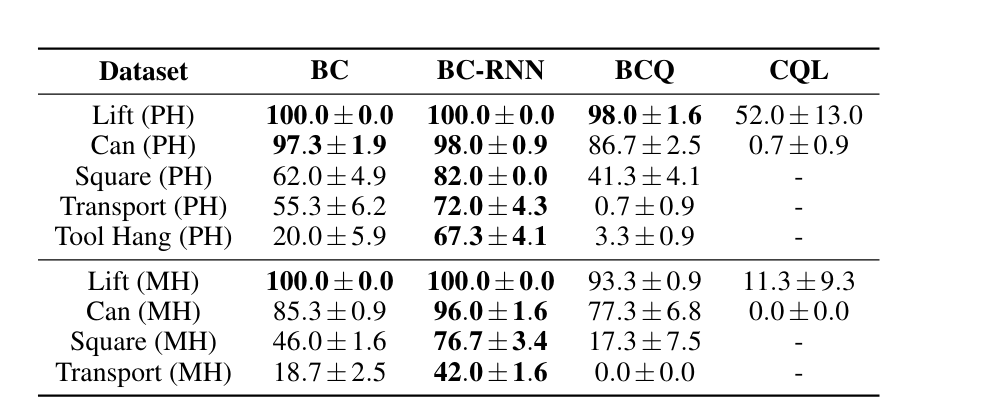
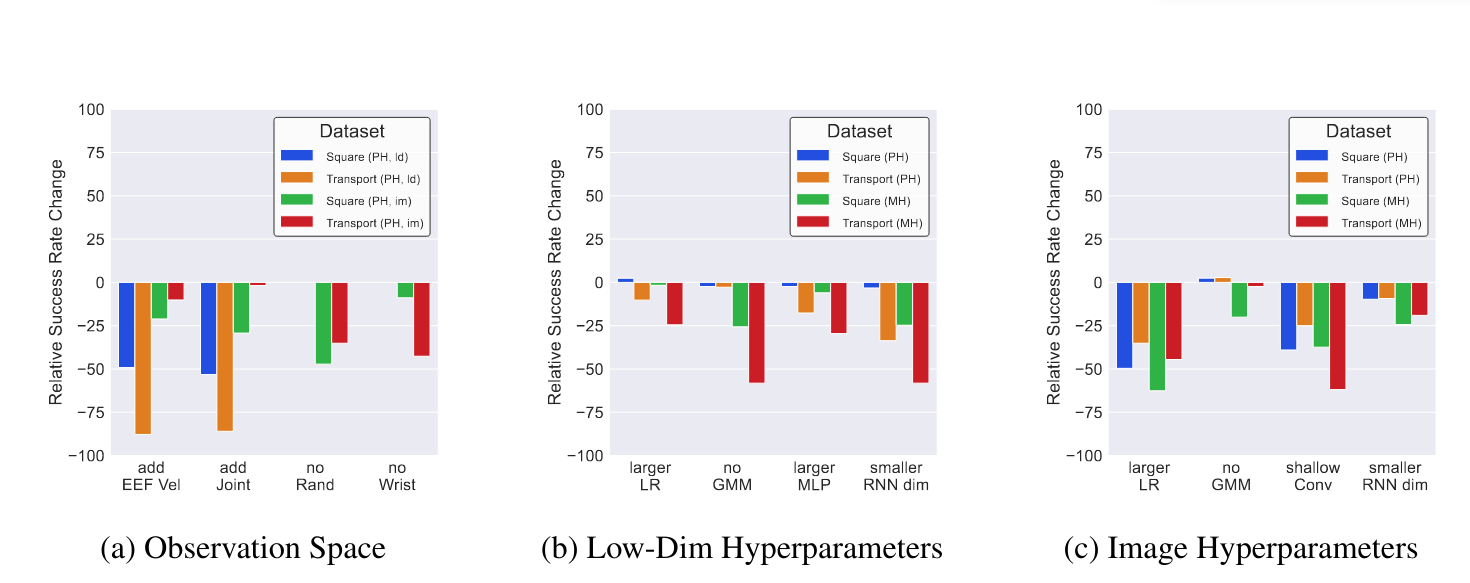
结论:
- 在 image 模式下的结论与 low_dim 模式下的结论一致。
- 用于机器人本体感知的特征是重要的。对 low_dim 模式,添加末端执行器的信息会严重伤害机器人(性能下降 49%~88%),但 image 模式就比较包容这个信息(性能下降 2%~29%),性能下降的可能原因是过拟合。
- 图像初始化和手腕的观察对操作任务是至关重要的。移除像素移动随机化和手腕相机会导致严重的性能下降。
超参数选择
图见上面。
- lr 从 1e-4 到 1e-3 变化,image 模式受很大影响而 low_dim 模式受影响小。
- 大的 MLP 网络也会降低性能。
- 浅层卷积网络代替 resnet 会降低性能。
- 减少 RNN 隐藏层维度会降低性能。
- 使用 GMM 策略和 resnet 编码器效果好。
最佳模型选择
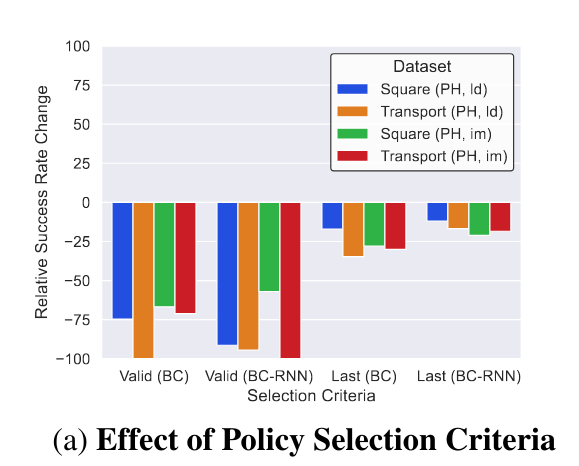
离线学习的最佳模型选择具有挑战性。左图是选择 val_loss 最小的模型或者最后一个 ckpt 与该策略的最佳模型的结果对比,可见选择最佳模型是 non-trivial 的。
数据集大小的影响
注意到,不太复杂的任务(Lift Can)可以使用一小部分数据产生熟练的策略(成功率75 % ~ 100 %)。其次,在更复杂的任务(Square Transport)上训练的政策在使用50 %或20 %的数据时受到了很大的影响。
转移到真实世界
训练的机器人可以熟练的掌握 Lift 和 Can 任务,非常难的 Tool Hang 任务也可以取得一定成功(3.3%)。这表明在模拟中训练出来的模型是有潜力转移到现实中的。
结论与探讨
- 具有时间抽象性的模型可以非常有效地从人类数据集中学习。
- 需要提高批量(离线) RL从次优人体数据集学习的能力。
- 改善离线的政策选择对于现实世界的设定很重要。
- 观测空间的作用很大,超参数也很重要。
- 利用大规模的人类数据集来解决更复杂的任务是很有希望的。
- 研究结果转移到真实世界环境中。
本周报告(2025.1.3 – 2025.1.10)
工作
- 阅读完 Robomimic 论文,并写完论文阅读笔记;
- 配置 robomimic 环境(需要 robomimic 版本为 1.4.0),根据教程实现了一个简单的 low_dim 模式下的 BC 模型,在 Lift 任务上取得了 98% 的成功率,视频保存在
/home/ljr/embodied/robomimic/bc_trained_models/test/20250104171913/videos;

下周工作
- 观察如何将 robomimic 训练出的模型接入 robosuite 中(如何直接加载训练模型?)并观察效果;
- 尝试抛开 robomimic 框架训练一个简单的 Lift 任务模型,以熟练掌握机器人使用的具体代码而不是调用 API。
问题
在训练时会报错,但不影响训练,可能是因为我的 linux 系统有桌面,导致 OPENGL 库报错。
1 | |
- 减少现实和仿真的gap 论文(不局限具身智能,包括自动驾驶等);
- Droid、simplerenv、libero、genesis 图像,输入VLM(qwen VL2),在 last
hidden state 和 embedding的输出有没有明显区别(具体什么区别需要判定),总结规律; - 不同亮度的图像(Droid)在last hidden state 和 embedding 的输出是否
有区别,设置合理的prompt。
本周报告(2025.2.16 – 2025.2.20)
工作
- sim2real 方式的论文和方法:
-
域随机化:通过引入随机性扩展机器人在模拟器中的操作范围,使得模拟环境能够迁移这些能力到现实场景(https://arxiv.org/abs/2310.04517 等);
-
域适配:旨在统一模拟环境与真实环境的特征空间,从而在统一特征空间内完成训练和迁移(https://ieeexplore.ieee.org/document/10153686 等);
-
干扰学习:在模拟环境中引入干扰,训练机器人策略,使其能够在充满噪声和不可预测性的现实环境中高效运行(https://arxiv.org/abs/2303.04137 等)。
-
Manibox,主要思想为利用规模化(scalable)、自动化的生成action数据,通过policy generalization方法来有效解决了空间泛化性问题,借助 YOLO-World 这样的开集检测模型,ManiBox 精准提取多视角的低维空间信息,将复杂的高维视觉问题转化为简化的状态建模问题,最后通过训练一个基于状态的策略(state-based policy),实现了从仿真到真实世界的高效迁移。结合随机掩码(random mask)技术和历史轨迹信息,ManiBox显著提升了策略在应对视觉噪声和检测失败场景下的鲁棒性。
-
RoboGSim,主要思想为利用3D Gaussian Splatting(3DGS)来高保真的重建场景,并对机械臂关节的点云进行分割。随后,通过 MDH 动态模型控制与各关节对应的点云,从而实现机械臂的动态渲染。可用来合成数据和评估数据。
- VLM 输入图像
已经实现将 Droid 三个相机拍出的视频输入 VL2 网络,但出现问题:text_prompt 输出为空,正在找原因。
1 | |
- 大模型的训练流程
-
预训练阶段(Pretraining)
目标:通过无监督学习的方式,让模型学习语言的通用规律和模式,形成基础的语言理解能力。
数据:使用海量的文本数据,如网络爬取的文本、书籍、论文等,数据量通常在2T~3T的token级别。
训练过程:模型通过自监督学习任务(如掩码语言模型MLM、下一句预测NSP等)进行训练,学习如何根据上下文预测缺失的单词或句子。 -
监督微调阶段(Supervised Fine-Tuning, SFT)
目标:在预训练模型的基础上,通过有监督学习的方式,使模型能够更好地完成特定任务,如对话、文本生成等。
数据:使用人工标注的指令数据或特定任务的数据,数据规模相对较小,但质量较高。
训练过程:对预训练模型进行微调,使其适应特定的任务需求。 -
奖励模型训练阶段(Reward Modeling)
目标:训练一个奖励模型,用于评估生成文本的质量,并为强化学习阶段提供奖励信号。
数据:使用人工标注的偏好数据,即对生成文本的质量进行排序。
训练过程:通过比较不同生成文本的质量,训练奖励模型。 -
强化学习阶段(Reinforcement Learning, RL)
目标:利用奖励模型的反馈,进一步优化模型的生成能力,使其生成的文本更符合人类偏好。
训练过程:使用强化学习算法(如PPO、DPO等),根据奖励模型的评分对模型进行优化。 -
参数计算
主要参数为 transformer 层的参数,L 层transformer,隐藏维度为 h,词表嵌入大小为 V,那么具体参数量为
一个 7B 模型,有 70 亿参数,储存时每个参数以 fp16(2个字节) 格式存储,那么大小为
- 推理、训练显存
推理时看量化,在32fp下 1B 参数对应 3.75G 显存,int8 下对应 0.9G 显存;
训练时需要的显存是至少推理的9-10倍。
本周报告(2025.2.21 – 2025.2.27)
工作
- 调整不同数据集的亮度,判断其 embed 和 last hidden state 输出有什么区别;
- 获取数据集:一共使用了四个数据集,其情况如下表所示:
| 数据集名称 | 获取方式 | 相机视角 | 机械臂种类 | 样例图片 |
|---|---|---|---|---|
Droid |
真实 | 三个相机视角,exterior_1_left, wrist,exterior_2_left |
Franka |  |
Simpler_env |
仿真 | 单一固定视角,从样例视频生成 | Google robot |  |
Genesis |
仿真 | 多视角,可配置相机位置,主要配置了左中右三种相机位置,从样例视频生成 | Franka |  |
Libero |
仿真 | 两个相机视角,agentview, wrist,是给好的数据集 |
Franka |  |
-
更改亮度的代码:在照片左上角增加一个点光源
1
2
3
4
5
6
7def add_point_light(
image_path,
center_position, # 光源中心坐标 (x, y)
radius=100, # 光源半径
brightness=1.5, # 亮度增强因子(1.0为原图)
light_color=(255, 255, 255) # 光源颜色(默认为白色)
):Droid 原始图片:

Droid 添加点光源后:

-
判断向量之间的差异:主要是使用了余弦相似度和 MSE ,后面列出的数据皆为余弦相似度
1
2
3
4
5
6
7
8def compare_vectors(vec1, vec2, method="cosine"):
"""比较两个向量的差异,支持余弦相似度或MSE"""
if method == "cosine":
cos = torch.nn.CosineSimilarity(dim=0)
return cos(vec1.flatten(), vec2.flatten()).item()
elif method == "mse":
mse = torch.nn.MSELoss()
return mse(vec1, vec2).item() -
最终结果
可以看出, gap 比较大的是 Libero 数据集,其它数据集的余弦相似度都在 0.8 以上。模型 平均嵌入向量比较(平均值) 平均最后隐藏层比较(平均值) DroidGenesisLiberoSimpler
- 不同数据集的图片输入
qwen2-VL,其embed和last hidden state输出有什么区别
-
仍然是对四张数据集的图片,进行统一化处理(即都
resize为 224*224),并输入qwen2-vl模型中,这样可以保证输出的向量维度一样; -
对不同数据集的各种向量计算余弦相似度,得到的结果如下:
| 数据集对比 | 嵌入向量相似度(平均值) | 最后隐藏层相似度(平均值) |
|---|---|---|
DROID vs Genesis |
||
DROID vs Libero |
||
DROID vs Simpler |
||
Libero vs Genesis |
||
Libero vs Simpler |
从结果可以观察到:
- 大多数情况下,最后隐藏层的相似度比嵌入向量的相似度更高,这可能表明最后隐藏层包含了更丰富的特征信息
- Libero 和 Genesis 数据集之间的相似度最高,说明这两个数据集的图像特征可能更接近
- 整体相似度都在 0.45-0.66 之间,表明不同数据集之间存在一定的差异性
下周任务
- 尽量调好适配 Droid 数据集的相机,让不同数据集拍出来的图片是同一个角度的(
exterior_1_left,wrist,exterior_2_left);genesis可以手动调节相机,但是 libero 是给定的数据,不能直接在数据集上进行修改。所以如何修改呢? - 在收集好数据后再进行向量的对比。
- 待续
本周报告(2025.2.28 – 2025.3.6)
工作
- 为输出的向量增加了方差的对比;
- 为给图片增加亮度提供了新方法:给图片像素值整体扩大或缩小倍数,分别取了 四个数值进行对比;
- 修改 prompt,如果数据集给出了 prompt 的话就把这个 prompt 输入到 qwen2-VL 中,否则使用默认的 prompt。
- 基本对齐了 genesis 和 droid 的左右视角,并进行了这两个数据集输出的对比。
Droid 余弦相似度和方差比较
| 指标类型 | 点光源图片 | 亮度因子 0.8 | 亮度因子 0.9 | 亮度因子 1.1 | 亮度因子 1.2 | 原始图片 |
|---|---|---|---|---|---|---|
| 嵌入向量相似度(对应提示词) | 0.8093 | 0.9265 | 0.9532 | 0.9167 | 0.8650 | - |
| 嵌入向量相似度(默认提示词) | 0.8102 | 0.9263 | 0.9548 | 0.9129 | 0.8649 | - |
| 最后隐藏层相似度(对应提示词) | 0.8272 | 0.9173 | 0.9438 | 0.9170 | 0.8815 | - |
| 最后隐藏层相似度(默认提示词) | 0.8150 | 0.9102 | 0.9404 | 0.9073 | 0.8729 | - |
| 嵌入向量方差(对应提示词) | 1.2931 | 1.5429 | 1.5708 | 1.5530 | 1.4533 | 1.5593 |
| 嵌入向量方差(默认提示词) | 1.3888 | 1.6548 | 1.6804 | 1.6636 | 1.5563 | 1.6642 |
| 最后隐藏层方差(对应提示词) | 23.5463 | 23.7557 | 23.8193 | 23.8476 | 23.7426 | 23.8269 |
| 最后隐藏层方差(默认提示词) | 23.1822 | 23.3891 | 23.4461 | 23.4846 | 23.3775 | 23.4565 |
Genesis 余弦相似度和方差比较
| 指标类型 | 点光源图片 | 亮度因子 0.8 | 亮度因子 0.9 | 亮度因子 1.1 | 亮度因子 1.2 | 原始图片 |
|---|---|---|---|---|---|---|
| 嵌入向量相似度(有提示词) | 0.9523 | 0.9254 | 0.9562 | 0.9385 | 0.9067 | - |
| 嵌入向量相似度(默认提示词) | 0.9518 | 0.9256 | 0.9562 | 0.9393 | 0.9069 | - |
| 最后隐藏层相似度(有提示词) | 0.8303 | 0.7665 | 0.8335 | 0.7974 | 0.7298 | - |
| 最后隐藏层相似度(默认提示词) | 0.8284 | 0.7660 | 0.8332 | 0.7982 | 0.7290 | - |
| 嵌入向量方差(有提示词) | 1.5404 | 1.5219 | 1.5288 | 1.5300 | 1.5355 | 1.5288 |
| 嵌入向量方差(默认提示词) | 1.5378 | 1.5214 | 1.5271 | 1.5276 | 1.5343 | 1.5263 |
| 最后隐藏层方差(有提示词) | 21.2368 | 21.2191 | 21.2396 | 21.3057 | 21.2890 | 21.2734 |
| 最后隐藏层方差(默认提示词) | 21.2306 | 21.2025 | 21.2302 | 21.2906 | 21.2698 | 21.2607 |
Libero 余弦相似度和方差比较
| 指标类型 | 点光源图片 | 亮度因子 0.8 | 亮度因子 0.9 | 亮度因子 1.1 | 亮度因子 1.2 | 原始图片 |
|---|---|---|---|---|---|---|
| 嵌入向量相似度(有提示词) | 0.7002 | 0.8791 | 0.9356 | 0.9280 | 0.8722 | - |
| 嵌入向量相似度(默认提示词) | 0.6972 | 0.8761 | 0.9383 | 0.9298 | 0.8768 | - |
| 最后隐藏层相似度(有提示词) | 0.7888 | 0.9113 | 0.9466 | 0.9335 | 0.9043 | - |
| 最后隐藏层相似度(默认提示词) | 0.7784 | 0.9018 | 0.9450 | 0.9289 | 0.8979 | - |
| 嵌入向量方差(有提示词) | 1.5132 | 1.3966 | 1.4318 | 1.4685 | 1.4725 | 1.5980 |
| 嵌入向量方差(默认提示词) | 1.6414 | 1.5044 | 1.5550 | 1.5926 | 1.5870 | 1.7395 |
| 最后隐藏层方差(有提示词) | 25.0966 | 24.8687 | 25.3594 | 24.9500 | 24.6622 | 26.2332 |
| 最后隐藏层方差(默认提示词) | 25.0144 | 24.4799 | 25.0843 | 24.6315 | 24.2859 | 26.0618 |
结论
- 对于最后隐藏层相似度来说,有对应提示词的图片的余弦相似度更高,说明有提示词的图片的特征提取效果更好;
- 对于嵌入向量方差来说,有对应提示词的图片的方差更小;而对于最后隐藏层方差,有对应提示词的图片的方差更大。
- 显然,所有的输出都是最后隐藏层方差远大于嵌入向量方差,说明最后隐藏层包含的特征信息更多。
Genesis和DROID的对比
下面是视角对齐后的 Genesis 和 DROID 的图片对比:

Genesis数据集
DROID数据集
回顾:未对齐时的数据
| 数据集对比 | 嵌入向量相似度(平均值) | 最后隐藏层相似度(平均值) |
|---|---|---|
DROID vs Genesis |
||
DROID vs Libero |
||
DROID vs Simpler |
||
Libero vs Genesis |
||
Libero vs Simpler |
对齐后的更详细数据:
| 指标 | DROID vs Genesis(对齐后) |
|---|---|
| 嵌入向量相似度 | |
| 最后隐藏层相似度 | |
| DROID嵌入向量方差 | |
| Genesis嵌入向量方差 | |
| DROID最后隐藏层方差 | |
| Genesis最后隐藏层方差 |
通过对比可以看出,对齐后的相似度(无论是嵌入向量还是最后隐藏层)都有所提升,说明对齐操作确实提高了两个数据集之间的相似性。
别的尝试
仿照 simpler_env 对 genesis 加一个桌子,目前正在进行试验(未成功)。
本周报告(2025.3.7 – 2025.3.13)
本周工作
- 实现光照变化、背景纯色和杂乱、相机抖动在仿真环境的代码,还未在训练和验证中测试;
- 修改了数据采集的代码,使得它在我的电脑上可以运行,并成功采集了一条数据;
- 正在训练一个基础模型用于测试。
光照变化
实现函数 add_lighting_effect,用于实现图像的光照变化。具体思路是光源可选择在四个角落,然后根据光源位置和图片大小,计算出每个像素点距离光源的距离,然后根据距离计算出光照强度,最后将光照强度乘以图片的像素值,得到光照变化后的图片。也就是说离光源越远,图像亮度变化越小。
1 | |
背景纯色和杂乱
使用传统计算机视觉的方法(像素颜色比较、膨胀和腐蚀)来找到属于背景的部分,对其加上mask。再选取任意杂乱图片作为背景,在mask=1的部分使用杂乱图片,mask=0的部分使用原图。
1 | |
相机抖动
利用传统计算机视觉的运动卷积来模拟模糊效果,用平移和旋转模拟相机抖动,注意平移的角度就是运动方向。
1 | |
最后处理图片的效果

数据收集
Libero 数据收集分为两个部分,一是通过键盘操作人工完成任务,这个时间段收集的数据只包含 action 和 state,感觉是用于复现的;二是通过上面采集的数据进行任务复现,同时再记录别的数据(如相机图像等等)。命令如下:
1 | |
跑通训练模型的代码
编写一个 run.sh 文件用于训练 libero object 10个任务的模型,目前已经训练到第9个任务。
1 | |
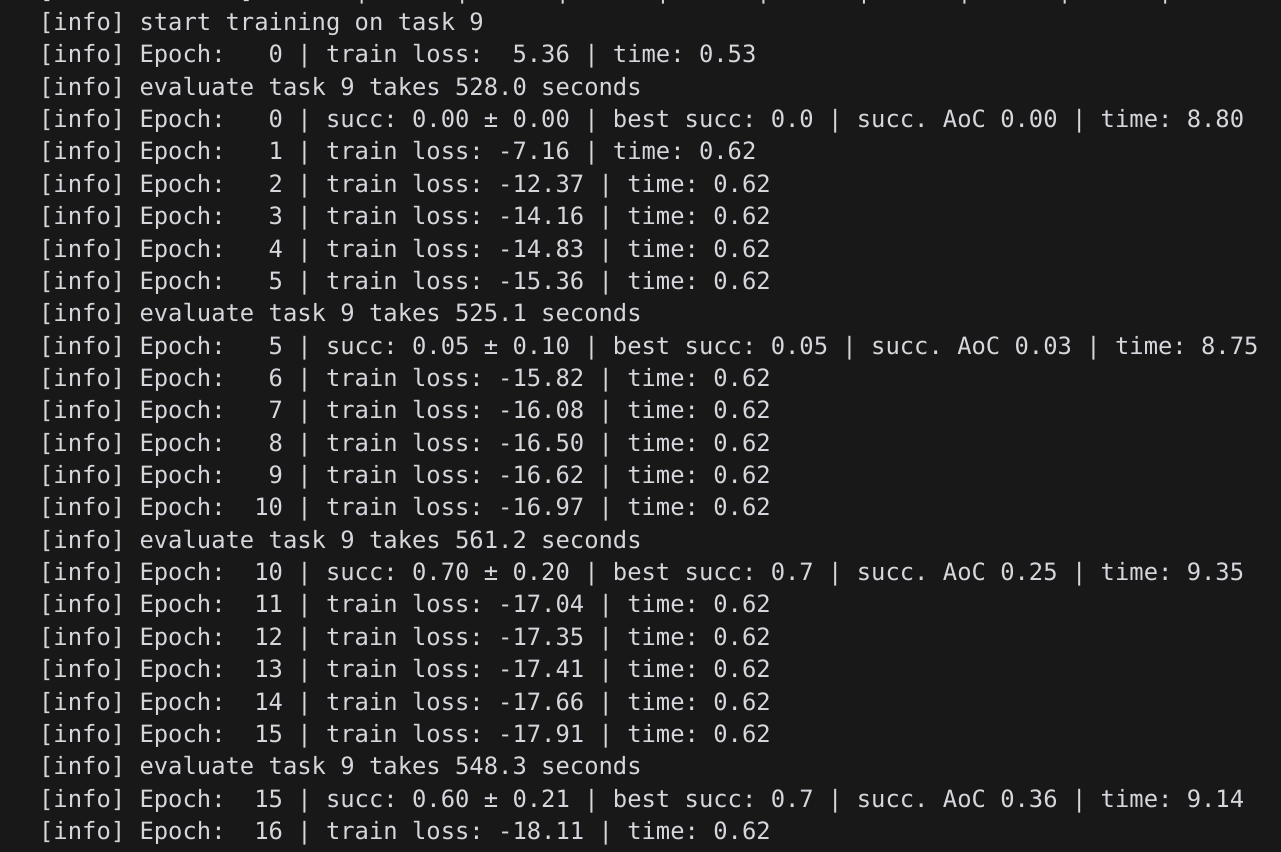
工作内容与问题记录
环境配置问题修复
-
MUJOCO_GL 环境变量设置
- 桌面环境:需要设置
export MUJOCO_GL=glx - 实验室环境:需要设置
export MUJOCO_GL=osmesa
- 桌面环境:需要设置
-
数据采集脚本修改1
在scripts/collect_demonstration.py中需要修改回调函数设置:1
2
3
4
5
6
7# 原代码
env.viewer.add_keypress_callback("any", device.on_press)
env.viewer.add_keyup_callback("any", device.on_release)
env.viewer.add_keyrepeat_callback("any", device.on_press)
# 修改后
env.viewer.add_keypress_callback(device.on_press)修改原因:
add_keypress_callback只接受一个参数env.viewer类没有add_keyup_callback和add_keyrepeat_callback方法
-
数据采集脚本修改2
在scripts/create_dataset.py中需要修改路径设置:1
2
3hdf5_path = os.path.join(get_libero_path("datasets"), bddl_file_dir.split("bddl_files/")[-1].replace(".bddl", "_demo.hdf5"))
# 修改为
hdf5_path = os.path.join(get_libero_path("datasets"), bddl_file_name.split("bddl_files/")[-1].replace(".bddl", "_demo.hdf5"))
修改原因:应该使用文件路径而不是文件夹路径,否则文件名中不会出现.bddl
-
pynput库bug修复
在文件pynput/_util/xorg.py第472行需要修改:1
2
3
4
5
6# 原代码
self._handle(self._display_stop, event, injected)
self._handle_message(self._display_stop, event, injected)
# 修改后
self._handle_message(self._display_stop, event, injected)推测原因:代码合并时未正确删除重复代码
下周工作
- 弄清楚 libero 自定义仿真环境的流程,并尝试自定义仿真环境;
- 在训练好一个 libero_object 10 个任务的模型后,在evaluation时对动作加入高斯噪声;
- 尝试使用深度学习的方式让背景识别更加精准(SAM?);
- …
待解决问题
数据采集环境选择:
- 服务器是headless环境,需要使用如
Xvfb等软件进行远程投屏(当前无权限安装) - 是否应该改为在本地电脑进行数据采集?
需要确定最佳的数据采集方案。
本周报告(2025.3.14 – 2025.3.20)
主要工作
本周主要完成了以下几个方面的工作:
- 背景图片替换:成功实现了仿真环境背景图片的替换。
- 模型训练与验证:完成了
libero_object10 个任务模型的训练,并验证了其准确率。 - 手柄控制适配:调整了学长的
xbox.py代码,适配了自己的手柄,解决了按键漂移问题。 - 数据采集与训练:使用手柄采集了新任务的数据,并进行了训练,获得了初步结果。
1. 背景图片替换
与之前的任务类似,本次任务通过替换墙壁的 texture 图片来实现背景的更换。具体步骤如下:
-
添加图片:在
/LIBERO/libero/libero/assets/textures文件夹下添加新的背景图片,例如flower.png。 -
修改样式文件:在
/LIBERO/libero/libero/envs/arenas/style.py文件中找到WALL_STYLE字典,添加"flower": "flower.png"。 -
应用纹理:在代码中指定使用该纹理图片:
1
2
3
4
5
6
7
8
9
10env_args = {
"bddl_file_name": task_bddl_file,
"camera_heights": 256,
"camera_widths": 256,
"scene_properties": {
"floor_style": "light-gray",
"wall_style": "flower", # customize wall style
}
}
env = OffScreenRenderEnv(**env_args) -
效果展示:替换后的效果比上周的计算机视觉识别方法更加清晰自然。

背景图片替换效果
2. 手柄控制适配
针对我的手柄特点(无背键、存在摇杆漂移),我对 xbox.py 进行了如下修改:
- 移除背键暂停代码:由于我的手柄没有背键,因此移除了相关代码。
- 调整灵敏度:根据手感调整了摇杆的灵敏度。
- 增加死区:设置了死区,将摇杆在小范围内的值置零,以消除摇杆漂移的影响。
注意: receive_controller 函数中 self.device = self.find_device('Xbox') 的 Xbox 需要根据实际设备名称进行修改(例如,学长的电脑上为 X-Box)。
修改后,可以使用手柄进行数据采集。
3. 数据采集与训练
我重复使用了 libero_object 的第一个任务,并在环境中增加了一瓶饮料。使用手柄采集了 50 条数据,并进行了训练。
- 环境修改:使用
.bddl文件添加了一瓶饮料(可从下面的视频中看出)。 - 任务注册:在多个文件中添加了新任务的信息,使其加入到 benchmark 中。
初步训练结果(50 epoch):AoC 值为 ,最高完成率为 ,效果不理想。
| 原始数据 | 我的数据 |
|---|---|
 |
 |
数据对比
分析:
- 原始数据采集流畅,可以同时移动多个视角,延迟较小。
- 手柄采集的数据较为僵硬,只能同时移动一个视角,控制不便。
- 更倾向于使用 spacemouse 进行数据采集。
后续:
将训练 epoch 增加到 200 后,模型准确率显著提高,且仍有增长空间。可以考虑进一步增加训练轮次。训练 Log 如下:
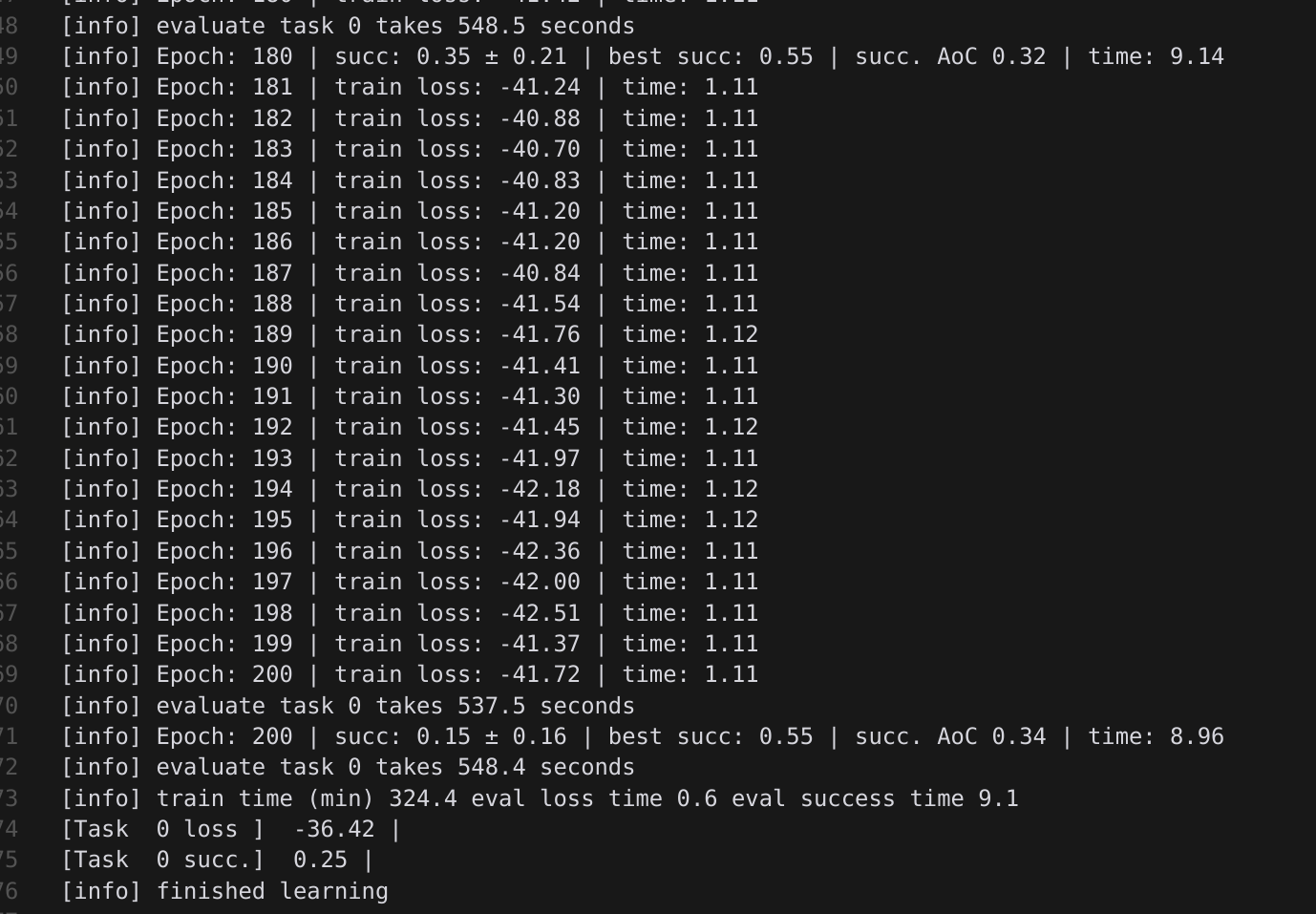
训练 Log
本周报告(2025.3.21 – 2025.3.27)
主要工作
- 阅读
Openvla,Octo论文,看看它们是怎么在虚拟环境下进行验证的,由此来创造并改进一些数据集; - 实现了一个新任务的创建(upsidedown);
- 思考了接下来的路线;
- 将代码上传到
github上。
阅读论文
Octo 论文的方法与 Libero 类似,可以认为是一个小的 VLA 模型,而Octo主要优势在于使用了vit作为处理图像的模型,具有更强大的泛化性;Openvla 的方法就是非常纯正的 VLA 模型。
Octo 和 Openvla 主要是在真实环境下进行训练和测试,但是可以给我创建数据集一些启发。
- 没见过的动作任务:Flip,Move_away,…
- 物品初始位置的变化:可以在任务创建的时候,给物品的初始化位置增加随机性,而不是几乎一样的位置(实现可能是增加随机数和随机交换位置),
或者随机把目标物品放在某件东西的上面,来测试模型对高度的泛化性; - 增加一个中途失败的判定:若碰倒了某样东西或者是把两样东西一起移到篮子里,则直接判定为失败;
- 模拟真实环境:花纹的变化,场景的变化(如厨房,卧室,客厅),光照的变化,相机随机抖动,动作数据高斯随机噪声;
实现新任务
这个基于 没见过的动作任务,在 Openvla 中,有一个 Flip 的任务,于是我发现可以给 libero 也增添一个差不多的任务:

思考路线
- 这个
benchmark是作为训练还是测试用的还是两者皆有? - 是否需要增加一个 vla 的
evaluate接口? - 是不是可以实现一个多卡训练?
- 是否应该抛弃
libero的非multitask的训练?这样的话我可以重新写一个evaluate.py。
本周报告(2025.4.11 – 2025.4.17)
主要工作
- 成功将
openpi模型转化为pytorch版本,并验证在相同输入下的输出结果的余弦相似度大于 ; - 成功把
libero_object数据集转化为RLDS格式,并用于微调octo-small模型; - 正在完成对
libero微调后的octo模型进行验证。
openpi 转化
-
思路:先把
pytorch版本的模型网络架构搭建起来,再去一层一层的对齐参数; -
难点:
-
multiheadattention的实现在q,k,v层的形状一样时,在pytorch中会把这三层合并起来,造成了对齐参数的困难;正确的转化代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33# 提取并处理 q,k,v 参数
q_kernel = jax_encoderblock['MultiHeadDotProductAttention_0']['query']['kernel'][i]
k_kernel = jax_encoderblock['MultiHeadDotProductAttention_0']['key']['kernel'][i]
v_kernel = jax_encoderblock['MultiHeadDotProductAttention_0']['value']['kernel'][i]
q_bias = jax_encoderblock['MultiHeadDotProductAttention_0']['query']['bias'][i]
k_bias = jax_encoderblock['MultiHeadDotProductAttention_0']['key']['bias'][i]
v_bias = jax_encoderblock['MultiHeadDotProductAttention_0']['value']['bias'][i]
# 获取形状参数
hidden_dim = q_kernel.shape[0]
num_heads = q_kernel.shape[1]
head_dim = q_kernel.shape[2]
q_kernel_reshaped = jnp.transpose(q_kernel, (1, 2, 0)).reshape(num_heads * head_dim, hidden_dim)
k_kernel_reshaped = jnp.transpose(k_kernel, (1, 2, 0)).reshape(num_heads * head_dim, hidden_dim)
v_kernel_reshaped = jnp.transpose(v_kernel, (1, 2, 0)).reshape(num_heads * head_dim, hidden_dim)
# 处理偏置
q_bias_reshaped = q_bias.reshape(num_heads * head_dim)
k_bias_reshaped = k_bias.reshape(num_heads * head_dim)
v_bias_reshaped = v_bias.reshape(num_heads * head_dim)
https://linux.do/
# 合并参数并释放临时变量
in_proj_weight = jnp.vstack([q_kernel_reshaped, k_kernel_reshaped, v_kernel_reshaped])
in_proj_bias = jnp.concatenate([q_bias_reshaped, k_bias_reshaped, v_bias_reshaped])
# 设置 PyTorch 注意力参数
img_torch.encoder.blocks[i].attn.in_proj_weight = torch.nn.Parameter(
torch.from_dlpack(in_proj_weight).to(device)
)
img_torch.encoder.blocks[i].attn.in_proj_bias = torch.nn.Parameter(
torch.from_dlpack(in_proj_bias).to(device)
) -
numpy不支持bfloat16运算,如何将jax权重转化为torch的权重; -
代码方案如下:
1
2
3
4# 对float32及其它
torch_tensor = torch.from_numpy(np.array(jax_tensor))
# 对bfloat16
torch_tensor = torch.from_dlpack(jax_tensor) -
如何规定 jax 模型在某张卡上跑?
-
-
最终经过 100 轮随机输入的对齐检测,结果如下表格:
模块 平均余弦相似度 平均绝对误差 imgllm
将 libero_object 数据集转化为 RLDS 格式
- 依赖于
openvla项目的转化方式,先对hdf5文件进行预处理(去除空步数等),再把预处理后的hdf5文件在链接中实现转化。 - 使用方式:
- 进入
libero/convert_raw_hdf5文件夹,在激活环境后运行以下预处理代码;1
2
3
4python convert_raw_hdf5/regenerate_libero_dataset.py \
--libero_task_suite libero_object \
--libero_raw_data_dir libero/datasets/libero_object \
--libero_target_dir libero/datasets/libero_object_no_noops - 进入对应的 libero_object 文件夹,在写好本地预处理数据集路径后,直接运行
tfds build即可。
- 进入
用Libero_RLDS数据微调octo
- 仿照
02_finetune.py来写微调文件, - 在
octo/data/oxe/oxe_standardization_transforms.py文件中添加预处理函数(是否需要?) - 自定义图像处理参数是否要加上?我觉得应该要加,但这里我没加。
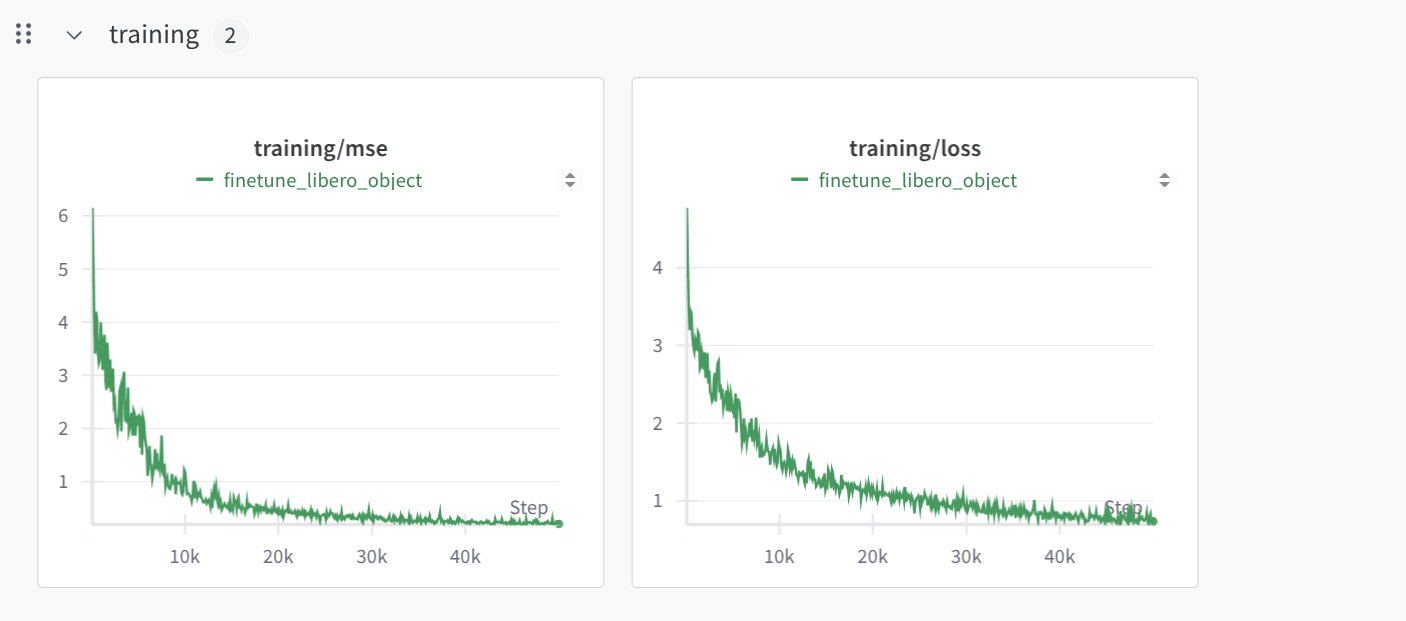
- 训练曲线:
对 libero 微调后的 octo 模型进行验证
-
使用
libero的验证环境,octo的微调后模型作为policy; -
目前结果不佳,怀疑是
finetune时的参数有问题,或者是推理代码中libero环境和octo模型没有很好的结合;- 要不要对输入的
obs也用oxe_standardization_transforms函数进行预处理? - 原始数据要不要经过像转化为
rlds时经过的处理? - 是不是语言编解码器的问题?
- 要不要对输入的
-
目前1次验证的视频,可以看到夹爪一路向右上角飘逸而去,这显然不是我想要的结果。
下周任务
- 完成
libero微调后模型的测试; - 收集
flip数据; - 用收集的
flip数据训练libero,octo?
Report This Week(2025.4.18 – 2025.4.14)
Main work
- Successfully finetune
octowithlibero_objectdataset, complete the evaluation code during and after training; - Collect trajectories the
fliptask in same initial states; - Backup core codes in server;
- Evaluate the libero_finetuned octo model ( epochs) in location OOD environment.
Finetune octo with libero
The bug last week that the Franka usually moves to topright corner is caused by not changing angentview images rotation by 180 degrees. The right code is following:
Right Preprocess Code
1 | |
After epochs training, model gets success rate in IID environment.
Collect flip trajectory
I collect trajectories in the almost same initial states, one of which is following:
I think I can up the sensitivity to make the actions more smooth.
Evaluate
Evaluation during training uses origin initial states, where the positions of objects barely change. So I evaluate the model in a location OOD, specifically each object’s position has a offset, where , meaning every location of item changes from to .

Origin Initial State

Test Initial State (OOD)
| Test Scenario | Success Rate | Number of Trials |
|---|---|---|
| IID (Original) | ||
| Location OOD |
Next Week’s Work
- Devise more dataset environments and collect corresponding data;
- Re-collect the
flipdata and make it more smooth; - Evaluate other OOD configurations: different backgrounds, lighting, gaussian noise in actions;
Report This Week(2025.5.8 – 2025.5.15)
Main Work
- 阅读了
MiniMind-V的代码架构,对其进行了分析; - 阅读了
openvla是如何由 VLM 模型转化为 VLA 模型的; - 初步安装好了
Isaac Sim,后续打算学习这个。
MiniMind-V
Openvla
VLM 模型转化为 VLA 模型主要依赖 ActionTokenizer。Openvla 中的ActionTokenizer 代码如下:
-
class ActionTokenizer::定义了一个名为ActionTokenizer的类,用于将连续的机器人动作离散化为 token。 -
def __init__(...):- 这是类的构造函数,用于初始化
ActionTokenizer的实例。 self.tokenizer, self.n_bins, self.min_action, self.max_action = tokenizer, bins, min_action, max_action: 保存传入的分词器、分箱数量、动作的最小值和最大值。self.bins = np.linspace(min_action, max_action, self.n_bins): 在动作的最小和最大值之间创建self.n_bins个均匀间隔的分箱边界。self.bin_centers = (self.bins[:-1] + self.bins[1:]) / 2.0: 计算每个分箱区间的中心点,用于后续将离散动作解码回连续值。self.action_token_begin_idx: int = int(self.tokenizer.vocab_size - (self.n_bins + 1)): 计算用于表示动作的 token 在词汇表中的起始索引。这里假设使用词汇表中最后n_bins + 1个 token 来表示动作。
- 这是类的构造函数,用于初始化
-
def __call__(self, action: np.ndarray) -> Union[str, List[str]]::- 这个方法使得
ActionTokenizer的实例可以像函数一样被调用,用于将连续动作编码为 token 字符串。 action = np.clip(action, a_min=float(self.min_action), a_max=float(self.max_action)): 将输入的连续动作值裁剪到预设的最小和最大动作值范围内。discretized_action = np.digitize(action, self.bins): 使用np.digitize将裁剪后的连续动作值离散化到对应的分箱索引。if len(discretized_action.shape) == 1:: 判断输入是单个动作还是批量动作。return self.tokenizer.decode(list(self.tokenizer.vocab_size - discretized_action)): 对于单个动作,将离散化的动作索引映射到词汇表中倒数的 token ID ,然后使用原始分词器解码为 token 字符串。
- 这个方法使得
-
def decode_token_ids_to_actions(self, action_token_ids: np.ndarray) -> np.ndarray::- 这个方法用于将离散的动作 token ID 解码回连续的动作值。
discretized_actions = self.tokenizer.vocab_size - action_token_ids: 将动作的 token ID 转换回离散化的动作索引(与编码过程相反)。discretized_actions = np.clip(discretized_actions - 1, a_min=0, a_max=self.bin_centers.shape[0] - 1): 对离散动作索引进行调整和裁剪。减 1 是因为np.digitize返回的索引从 1 开始,而self.bin_centers的索引从 0 开始。裁剪是为了防止索引越界。return self.bin_centers[discretized_actions]: 使用调整后的离散动作索引从self.bin_centers中获取对应的连续动作值(即分箱中心值)。
使用这个
ActionTokenizer方式如下:使用解读
这段代码展示了在模型训练或评估过程中,如何使用 ActionTokenizer 来处理和评估模型预测的机器人动作。
-
提取和过滤动作预测:
mask = action_gt > action_tokenizer.action_token_begin_idx:- 这是关键的一步,利用了
ActionTokenizer的action_token_begin_idx属性。这个属性定义了在分词器的词汇表中,专门用于表示离散化动作的 token ID 的起始位置。 - 通过比较真实的动作标签
action_gt是否大于这个起始索引,可以创建一个布尔掩码mask。这个掩码指明了哪些 token 实际上是有效的动作 token,而不是填充 token、文本 token 或其他特殊 token。后续的准确率和损失计算都将基于这个掩码,只考虑有效的动作部分。
- 这是关键的一步,利用了
-
计算动作准确率:
correct_preds = (action_preds == action_gt) & mask:- 首先比较预测的动作 token ID
action_preds和真实的动作 token IDaction_gt是否相等。 - 然后使用
& mask操作,确保只在有效的动作 token 位置(由mask指示)进行比较。
- 首先比较预测的动作 token ID
-
计算连续动作的 L1 损失:
continuous_actions_pred = torch.tensor(action_tokenizer.decode_token_ids_to_actions(action_preds[mask].cpu().numpy())):- 这里使用了
ActionTokenizer的核心功能之一:decode_token_ids_to_actions方法。 - 首先,
action_preds[mask]筛选出所有被模型预测为有效动作的 token ID。 action_tokenizer.decode_token_ids_to_actions(...)将这些离散的 token ID 解码回它们所代表的连续动作值(每个动作维度的分箱中心值)。- 最后,
torch.tensor(...)将解码得到的 NumPy 数组转换回 PyTorch 张量。
- 这里使用了
continuous_actions_gt = torch.tensor(action_tokenizer.decode_token_ids_to_actions(action_gt[mask].cpu().numpy())):- 对真实的动作标签执行相同的解码过程,得到真实的连续动作值。
action_l1_loss = torch.nn.functional.l1_loss(continuous_actions_pred, continuous_actions_gt):- 计算预测的连续动作和真实的连续动作之间的 L1 损失(平均绝对误差)。这提供了一个衡量模型预测的连续动作与真实动作接近程度的指标。