操作系统笔记
ARM操作系统汇编语言
aarch64常见指令
寄存器间的数据搬移指令
| 指令 | 含义 |
|---|---|
mov dst, src |
将src存储到dst寄存器中 |
add\sub\mul\div\neg Rd,Rn,Op2 |
将Rn Op2的计算结果储存到Rd中 |
lsl\lsr Rd,Rn,Op2 |
算数左\右移 Op2位 |
ror Rd,Rn,Op2 |
循环右移 Op2位 |
eor\orr\and Rd,Rn,Op2 |
按位异或\或\与 |
mvn Rd,Rn |
按位取反 |
ldr R,addr |
从内存mem[addr:addr+Rs]加载数据到寄存器R |
str R,addr |
从寄存器R将数据写入内存mem[addr:addr+Rs] |
寻址模式
- 基地址模式(索引寻址):
[rb] - 基地址加偏移量模式(偏移量寻址):
[rb, offset] - 前索引寻址(寻址操作前更新基地址):
[rb, offset]!
rb += Offset; 寻址M[rb] - 后索引寻址(寻址操作后更新基地址):
[rb], offset
寻址M[rb];rb += Offset
扩展指令
- 无符号扩展: uxtb, uxth, uxtw
把 8、16、32 字节的无符号数扩展到 32、32、64 位。由于无符号,所以扩展方式是加0; - 符号扩展: sxtb, sxth, sxtw
把 8、16、32 字节的有符号数扩展到 32、32、64 位。观察原来数的二进制最高位,如果是 1 则在前面加 1;否则加 0 。
例:sxtb x1, #0x80,这样x1中的32位数为#0xFFFFFF80,由于#0x80的二进制为1000 0000,所以给它的扩展前面应该加 1 ;
sxtb x2, #0x70,这样x2中的32位数为#0x00000070,由于#0x80的二进制为0111 0000,所以给它的扩展前面应该加 0 。
跳转指令
- 设置条件码:
- 通过s后缀数据处理指令隐式设置:
adds Rd, Rn, Op2
C:当运算产生进位时被设置
Z:当t为0时被设置
N:当t小于0时被设置
V:当运算产生有符号溢出时被设置 - 通过比较指令
cmp显式设置:cmp src1, src2
C:当减法不产生借位时被设置
Z:当两个操作数相等时被设置
N:当Src1小于Src2时被设置
V:当运算产生有符号溢出时被设置
- 跳转条件
| 条件 | 条件码组合 | 条件含义 |
|---|---|---|
| EQ | Z | 相等或为0 |
| NE | ~Z | 不等或非0 |
| MI | N | 负数 |
| PL | ~N | 非负数 |
| LT | N^V | 有符号小于 |
| LE | (N^V) | Z | 有符号小于或等于 |
| GT | ~(N^V) & ~Z | 有符号大于 |
| GE | ~(N^V) | 有符号大于或等于 |
| HI | C & ~Z | 无符号大于 |
| HS | C | 无符号大于或等于 |
| LS | ~C | Z | 无符号小于或等于 |
| LO | ~C | 无符号小于 |
- 跳转方式
- 以标签对应的地址作为跳转目标
无条件分支指令:b <label>
有条件分支指令:bcond <label>,例如beq,bne,ble - 以寄存器中的地址作为跳转目标,例如
br x0
函数调用
函数调用指令
bl label(直接调用,调用函数)blr Rn(间接调用,调用函数指针)- 功能:将返回地址存储在链接寄存器LR (x30寄存器的别名),跳转到被调用者的入口地址。
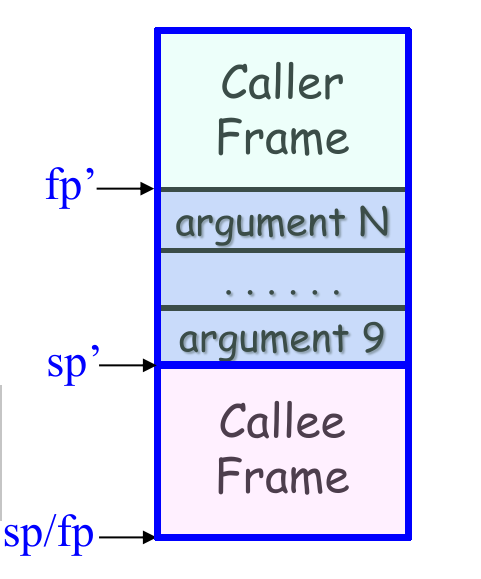
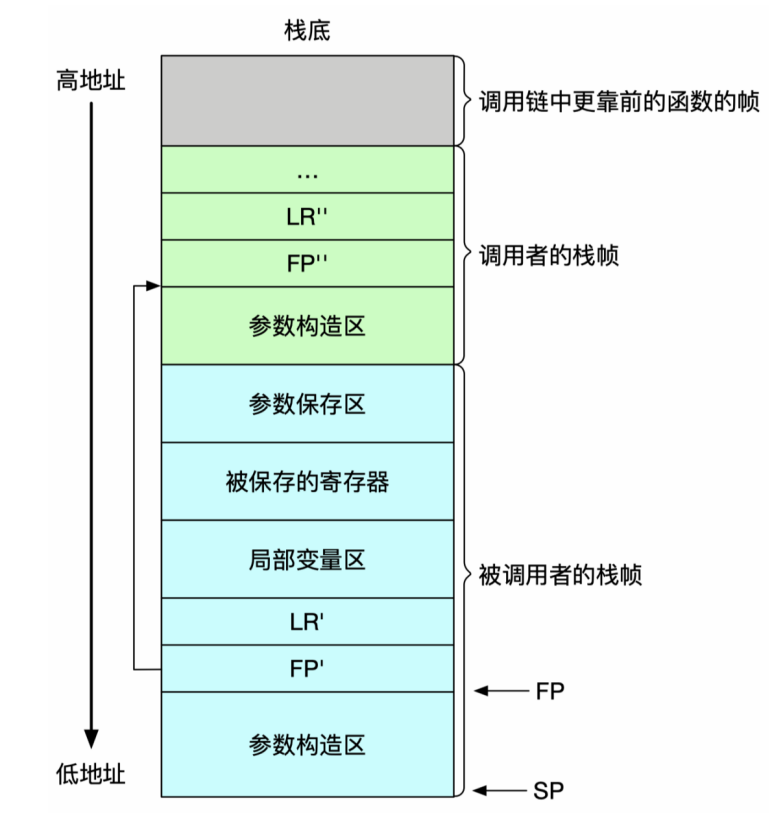
函数栈帧(Stack Frame)
- 是函数在运行期间使用的一段内存。
- 作用:存放其局部状态,包括存放返回地址、存放上一个栈桢的位置和存放局部变量等等。
- 特殊寄存器
SP指向栈顶(低地址),一般保存在x29寄存器中。
多级函数调用
需要先保存x29和x30寄存器的值,再把更新后的SP寄存器的值存到x29中,最后还原。
1 | |
函数参数与返回值
-
调用者使用x0 ~ x7寄存器传递前8个参数,被调用者使用x0寄存器传递返回值;

-
第8个之后的参数,按声明顺序从右到左,所有数据对齐到8字节,由调用者压到栈上。被调用者通过
SP+offset访问。
-
一个例子:
1
2
3
4
5
6
7
8
9
10
11void proc(long a1, long *a1p,int a2, int *a2p, short a3, short *a3p, char a4, char *a4p, char a5, char *a5p) {
*a1p += a1 ;
*a2p += a2 ;
*a3p += a3 ;
*a4p += a4 ;
*a5p += a5 ;
}
void caller(long *n) {
proc(1, 0x2000, 3, 0x4000, 5, 0x6000, 7, 0x8000, 9, 0xA000);
}汇编代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13mov x0, #0xa000
str x0, [sp, #8] // [sp + 8, sp + 16]保存#0xa000
mov w0, #0x9
strb w0, [sp] // [sp, sp + 8]保存#0x9,这两个参数保存在栈帧中
mov x7, #0x8000
mov w6, #0x7
mov x5, #0x6000
mov w4, #0x5
mov x3, #0x4000
mov w2, #0x3
mov x1, #0x2000
mov x0, #0x1
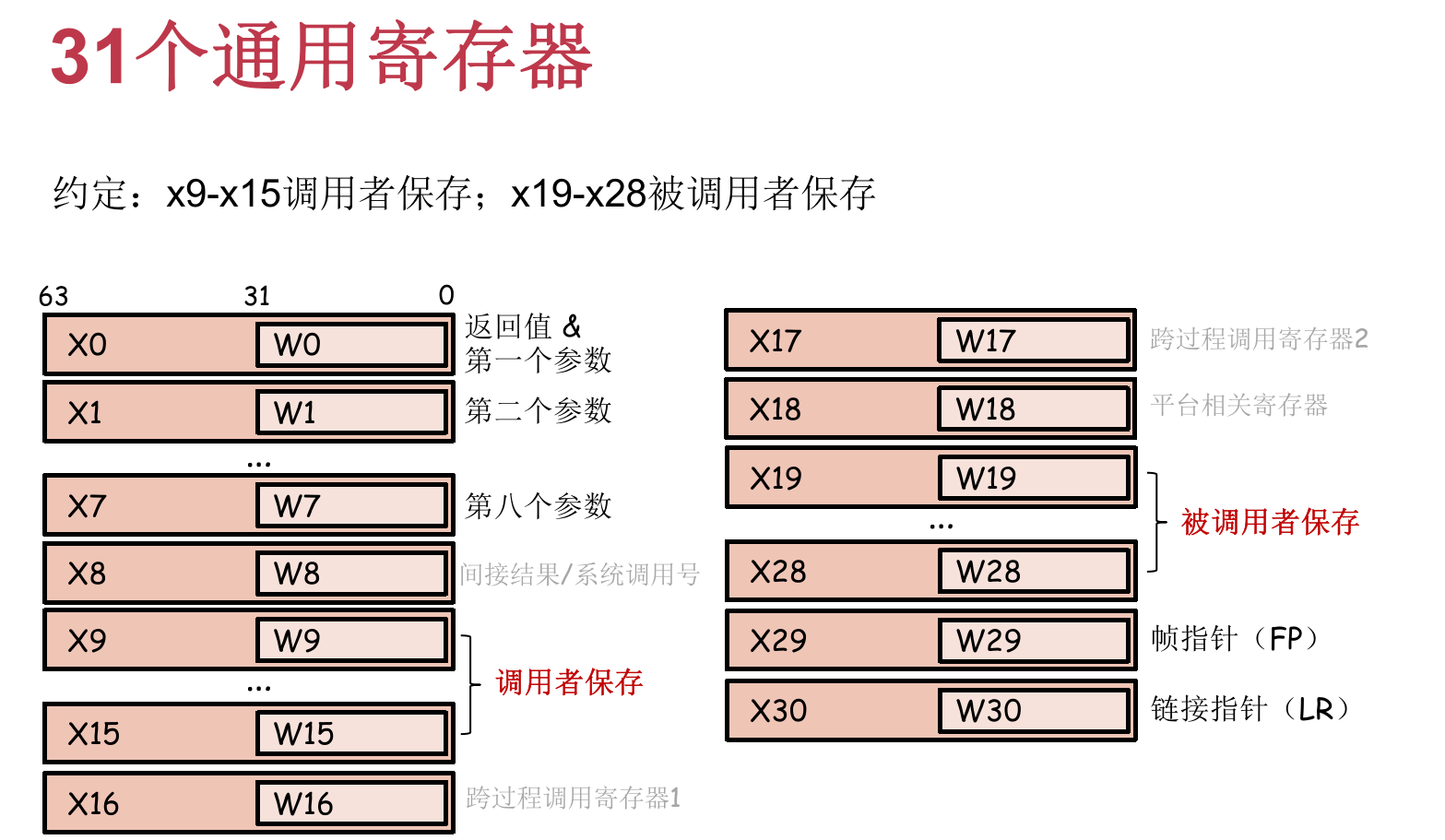
寄存器保存
通用寄存器保存
不同函数共享同一批通用寄存器,因此能够通过寄存器传递参数和返回值。然而,不同的函数对通用寄存器的使用会存在冲突 —— 覆盖。
函数在使用某个寄存器之前保存该寄存器的值,返回前恢复,保存在函数栈桢中。
-
调用者保存的寄存器包括 X9~X15,
调用者在调用前按需(仅考虑自己是否需要)进行保存,调用者在被调用者返回后恢复这些寄存器的值;
被调用者可以随意使用,这些寄存器调用后的值可能发生改变。 -
被调用者保存的寄存器包括 X19~X28,
被调用者在使用前进行保存,被调用者在返回前进行恢复。在调用者视角中,这些寄存器的值在函数调用前后不会改变。
例子:cube函数
1 | |
以下是它的汇编及解释:
1 | |
局部变量
函数局部变量存放在函数栈桢中。它们在分配栈帧时被一起分配,在返回前释放栈帧时释放,通过SP相对地址引用 (例如ldr x1, [sp, #8])。
一个例子
1 | |
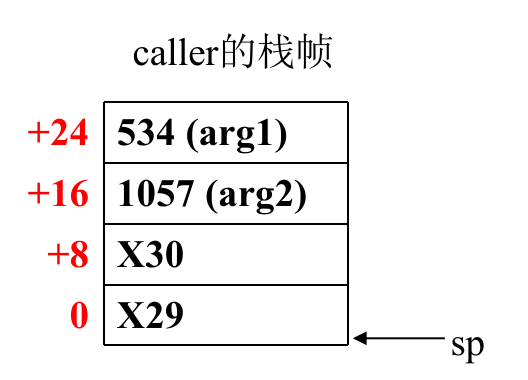
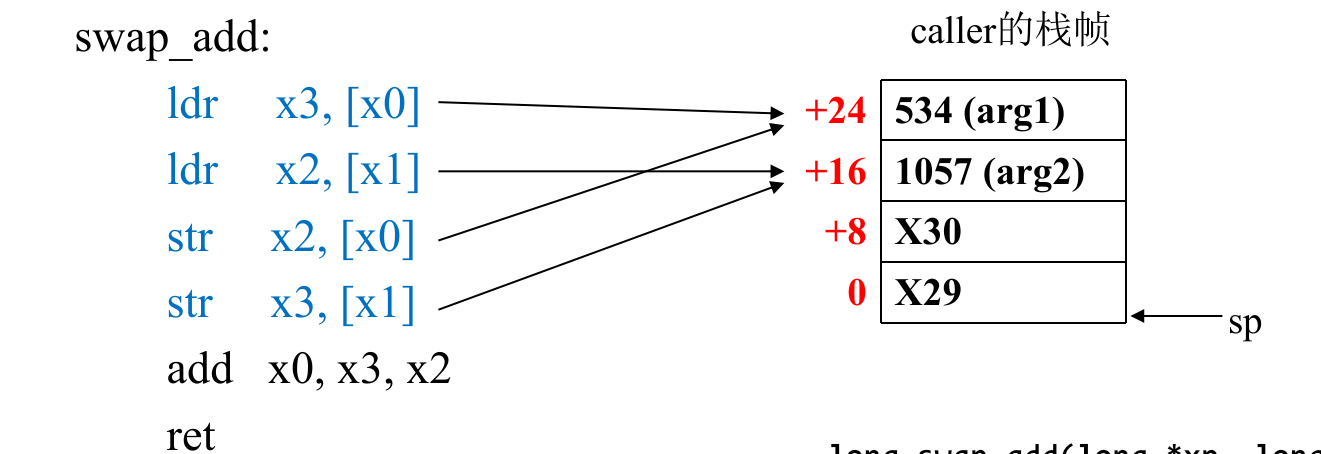
caller:
stp x29, x30, [sp, -32]!
# 开辟32个栈的位置,可以存四个八位数
mov x29, sp # 存下当前的SP寄存器
mov x0, #534
str x0, [sp, 24]
# mem[24, 32]存下534
mov x0, #1057
str x0, [sp, 16]
# mem[16, 24]存下1057
add x1, sp, #16
add x0, sp, #24
# 把栈上的数取下来作为函数的两个参数
bl swap_add
总结

系统ISA
如果所有的应用均能完全控制硬件计算资源,则会导致混乱。因此必须先让应用降权,不允许直接改变全局的系统状态。必须要有不同的权限级——至少两种权限:
- 低权限:不允许改变全局系统状态,用来运行应用
- 高权限:集中运行能改变全局系统状态的操作,形成了操作系统
特权操作:操作设备(读取文件、发送网络包…)、调整CPU频率、提供进程间通信…
特权级别
ARMv8.4特权级
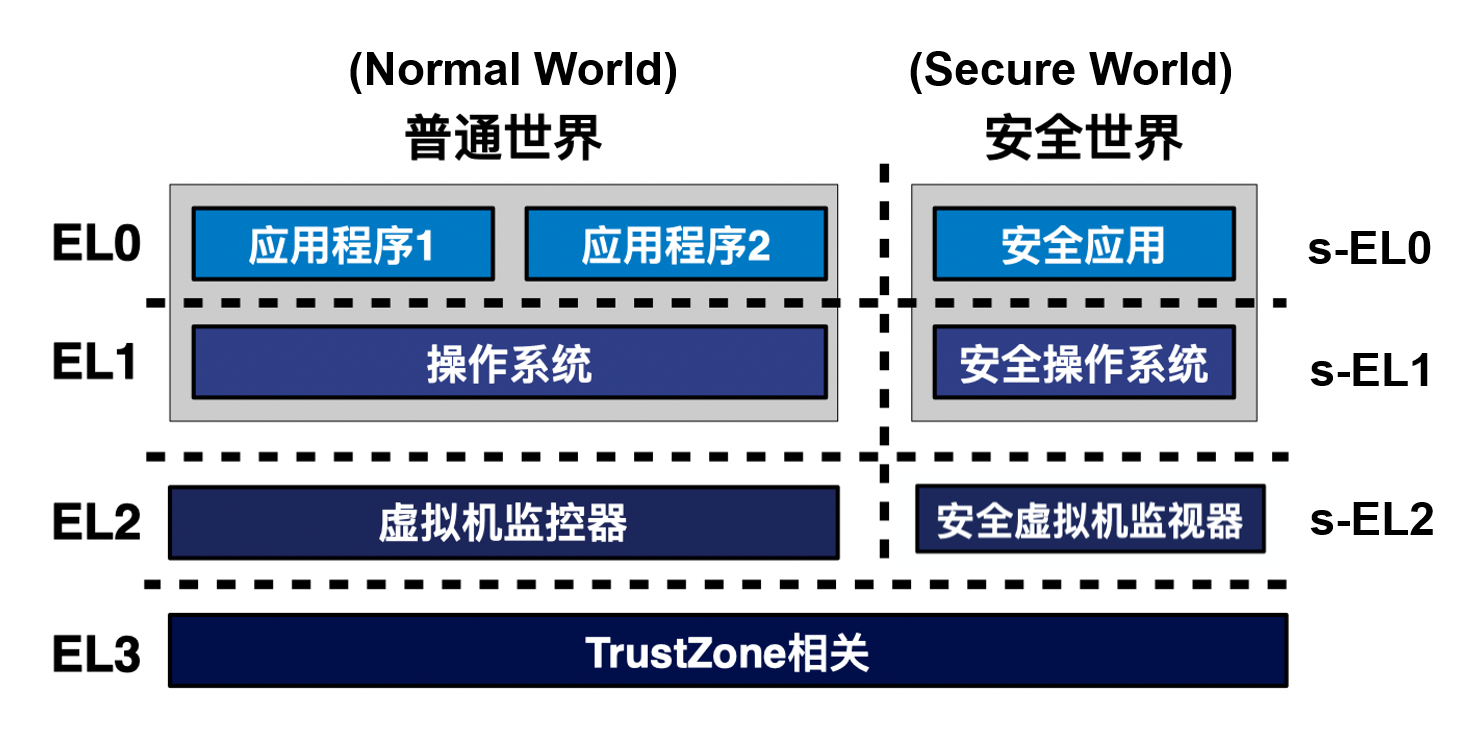
用户态(EL0)和内核态(EL1)
- 用户态(User-mode):只能使用用户 ISA
- 内核态(Kernel-mode):可以同时使用系统 ISA 和用户ISA
操作系统往往同时包含内核态与用户态的代码,如:Unix包含内核态的kernel 与用户态的 shell。
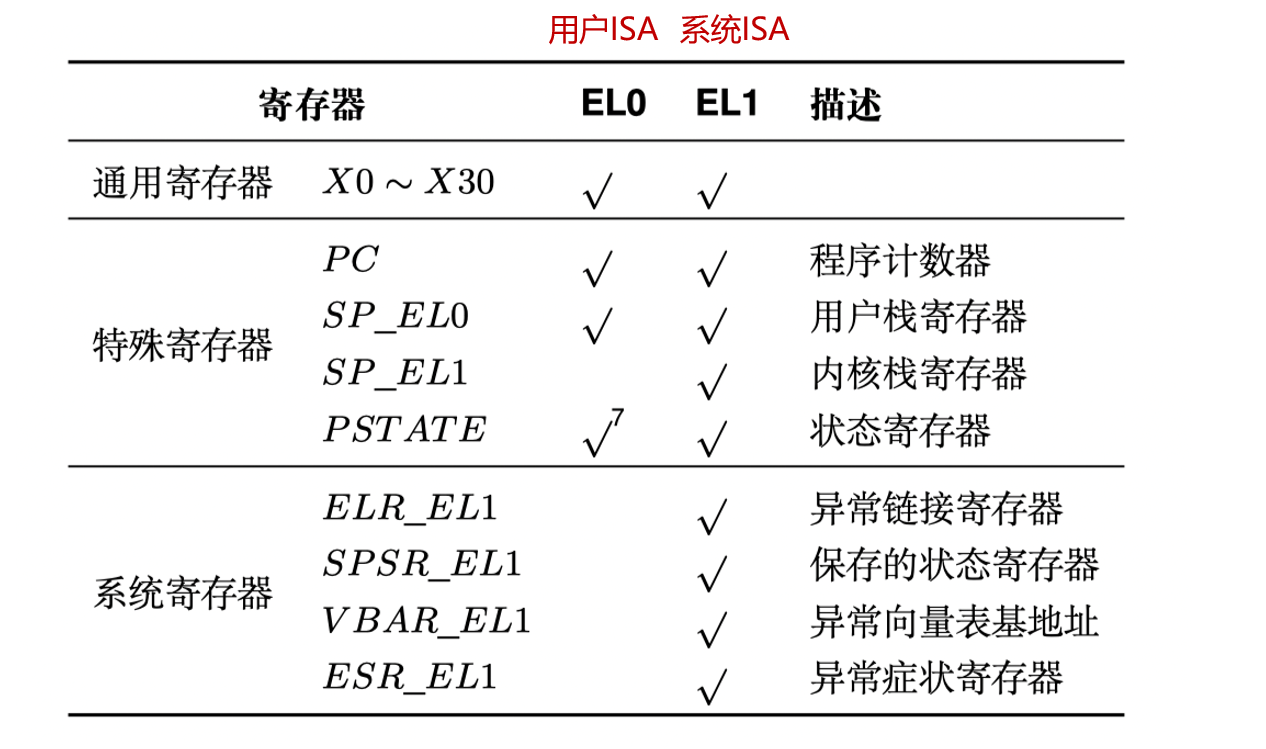
AArch64 中常见寄存器在不同特权级的可见情况
特权级切换
特权级切换的必要性
将CPU控制权移交给内核,使应用程序可以向操作系统请求服务,使操作系统能够切换不同应用程序执行,否则无法处理错误/恶意程序死循环。
何时发生特权级切换:在发生异常时
- 同步异常
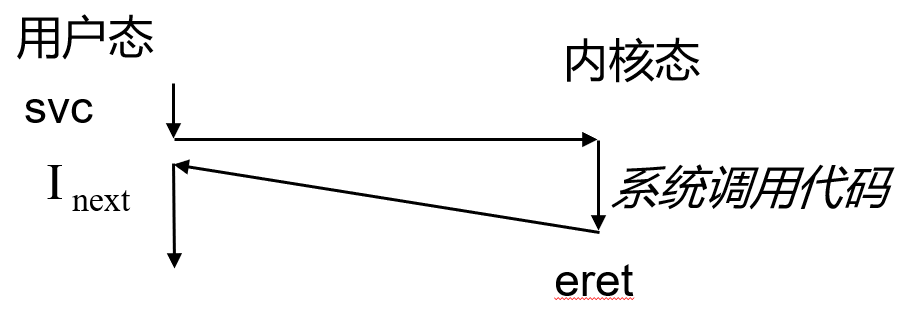
执行当前指令触发异常。- 用户程序主动发起:svc指令(OS利用eret指令返回)
- 非主动,例如用户程序意外访问空指针:普通ldr指令(OS“杀死”出错程序)
- 异步异常
CPU收到中断信号。- 从外设发来的中断,例如屏幕点击、鼠标、收到网络包;
- CPU时钟中断,例如定时器超时。
异常处理函数
异常处理函数属于操作系统的一部分,是运行在内核态的代码。异常处理函数完成异常处理后,将通过下述操作之一转移控制权:
- 回到发生异常时正在执行的指令;
- 回到发生异常时的下一条指令;
- 将发生异常事件的指令地址保存在ELR_EL1中;
- 将异常事件的原因保存在ESR_EL1。例如,是执行svc指令导致的,还是访存缺页导致的;
- 将处理器的当前状态(即PSTATE)保存在SPSR_EL1;
- 栈寄存器不再使用SP_EL0(用户态栈寄存器),开始使用SP_EL1(内核态栈寄存器,需要由操作系统提前设置);
- 修改PSTATE寄存器中的特权级标志位,设置为内核态;
- 找到异常处理函数的入口地址,并将该地址写入PC,开始运行操作系统(根据VBAR_EL1寄存器保存的异常向量表基地址,以及发生异常事件的类型确定)。
从用户态到内核态(eret)的任务:
- 将SPSR_EL1中的处理器状态写入PSTATE中(处理器状态也从 EL1 切换到 EL0);
- 栈寄存器不再使用SP_EL1,开始使用SP_EL0(注意:SP_EL1的值并没有改变;下一次下陷时,操作系统依然会使用这个内核栈);
- 将ELR_EL1中的地址写入PC,并执行应用程序代码。
操作系统在切换过程中的任务:
- 主要任务:将属于应用程序的 CPU 状态保存到内存中,用于之后恢复应用程序继续运行;
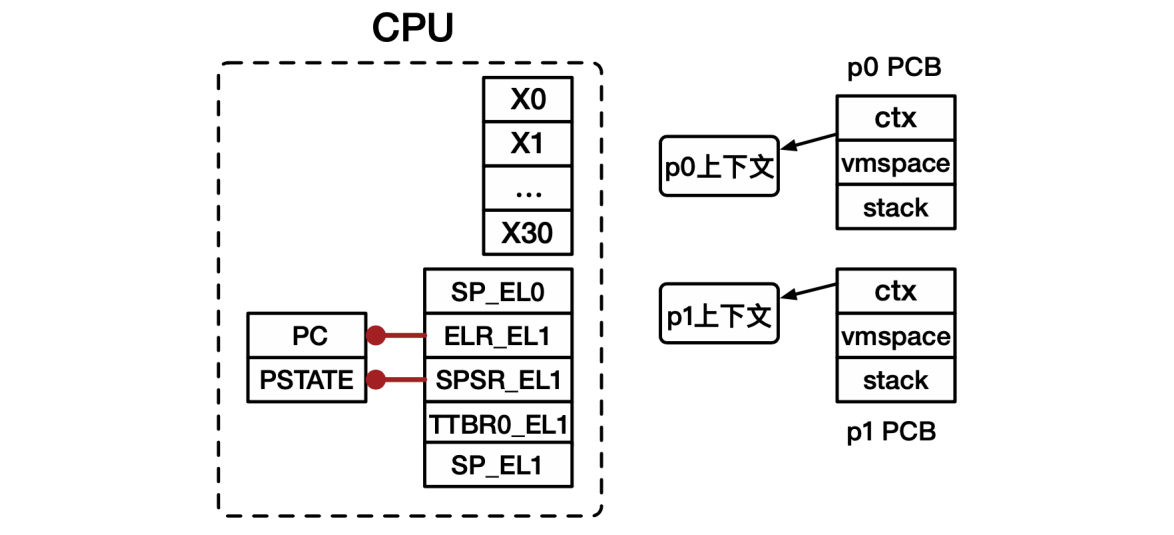
- 应用程序需要保存的运行状态称为处理器上下文。处理器上下文(Processor Context),是应用程序在完成切换后恢复执行所需的最小处理器状态集合。处理器上下文中的寄存器具体包括:
- 通用寄存器 X0-X30;
- 特殊寄存器,主要包括PC、SP和PSTATE;
- 系统寄存器,包括页表基地址寄存器等。
系统调用
硬件提供了一对指令svc/eret指令在用户态/内核态间切换。系统调用是用户与操作系统之间,类似于过程调用的接口,它通过受限的方式访问内核提供的服务。
AArch64常见的Linux的系统调用
| 编号 | 名称 | 描述 | 编号 | 名称 | 描述 |
|---|---|---|---|---|---|
| 17 | getcwd | Get current working directory | 129 | kill | Send signal to a process |
| 23 | dup | Duplicate a file descriptor | 172 | getpid | Get process ID |
| 56 | openat | Open a file | 214 | brk | Set the top of heap |
| 57 | close | Close a file | 215 | munmap | Unmap a file from memory |
| 63 | read | Read a file | 220 | clone | Create a process |
| 64 | write | Write a file | 221 | execve | Execute a program |
| 80 | fstat | Get file status | 222 | mmap | Map a file into memory |
| 93 | _exit | Terminate the process | 260 | wait4 | Wait for process to stop |
系统调用例子
1 | |
系统调用编号放在x8中,传参还是x0-x7。汇编代码如下:
1 | |
系统调用优化
VDSO
系统调用的时延不可忽略,其是调用非常频繁的情况。为了降低系统调用时延,如果没有特权级切换,那么就不需要保存恢复状态。
“gettimeofday” 在编译时作为内核的一部分。在用户态运行时,将"gettimeofday"的代码加载到一块与应用共享的内存页,这个页称为:VDSO。Time 的值同样映射到用户态空间(只读),只有在内核态才能更新这个值。
Flex-SC
在不切换状态的情况下实现系统调用。引入 system call page ,由 user & kernel 共享。用户进程可以将系统调用的请求 push 到 system call page,内核会从system call page poll system call 请求。将系统调用的调用和执行解耦,可分布到不同的CPU核。
单核也可以优化。
从应用视角看操作系统抽象
进程
分时复用有限的CPU资源。让多个应用程序轮流使用处理器核心。
- 何时切换:操作系统决定,运行时间片(例如100ms)
- 高频切换:看起来是多个应用“同时”执行
进程在操作系统中的实现是状态数据。
- 进程标识号(Process ID, PID)
- 运行状态:处理器上下文(CPU Context)
- 地址空间
- 打开的文件
进程切换
处理器上下文(CPU Context)
操作系统为每个进程维护处理器上下文,其中包含恢复进程执行所需要的状态。进程A执行到main函数任意一条指令,切换到进程B执行,一段时间后,再切回到进程A执行,需要保存一些值来切换回来。
具体包括:PC寄存器值,栈寄存器值,通用寄存器值,状态寄存器值。
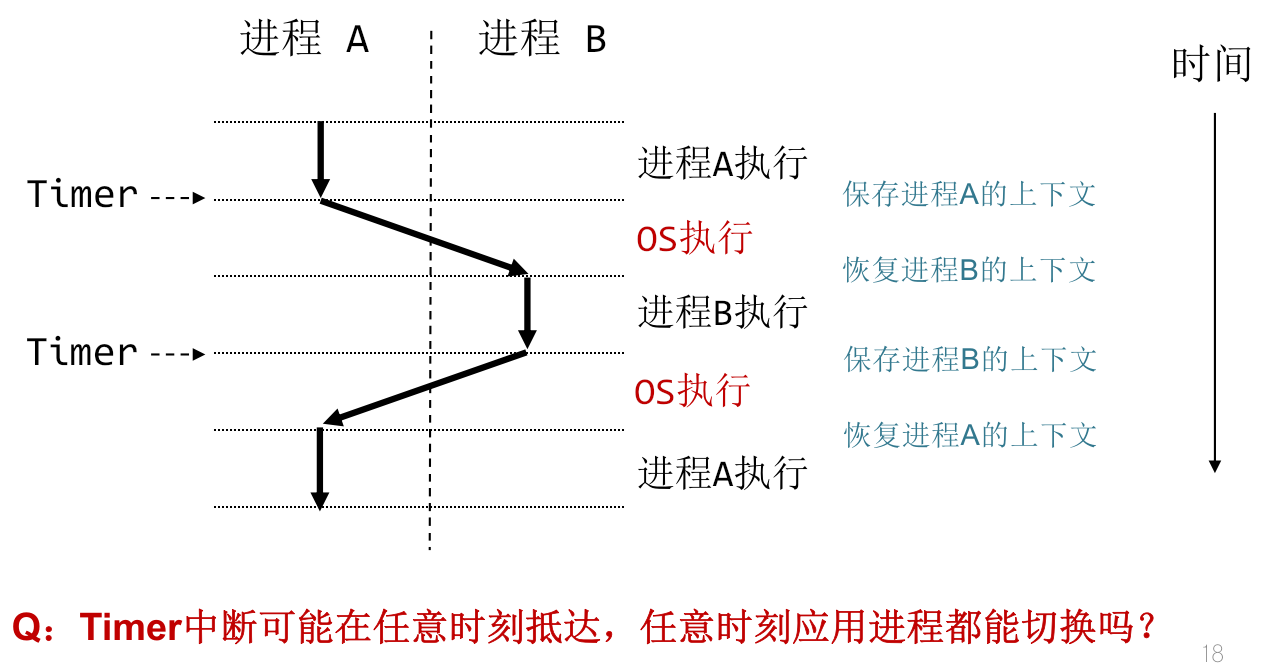
进程切换时机
-
异常导致的上下文切换,如Timer中断(如基于时间片的多任务调度);
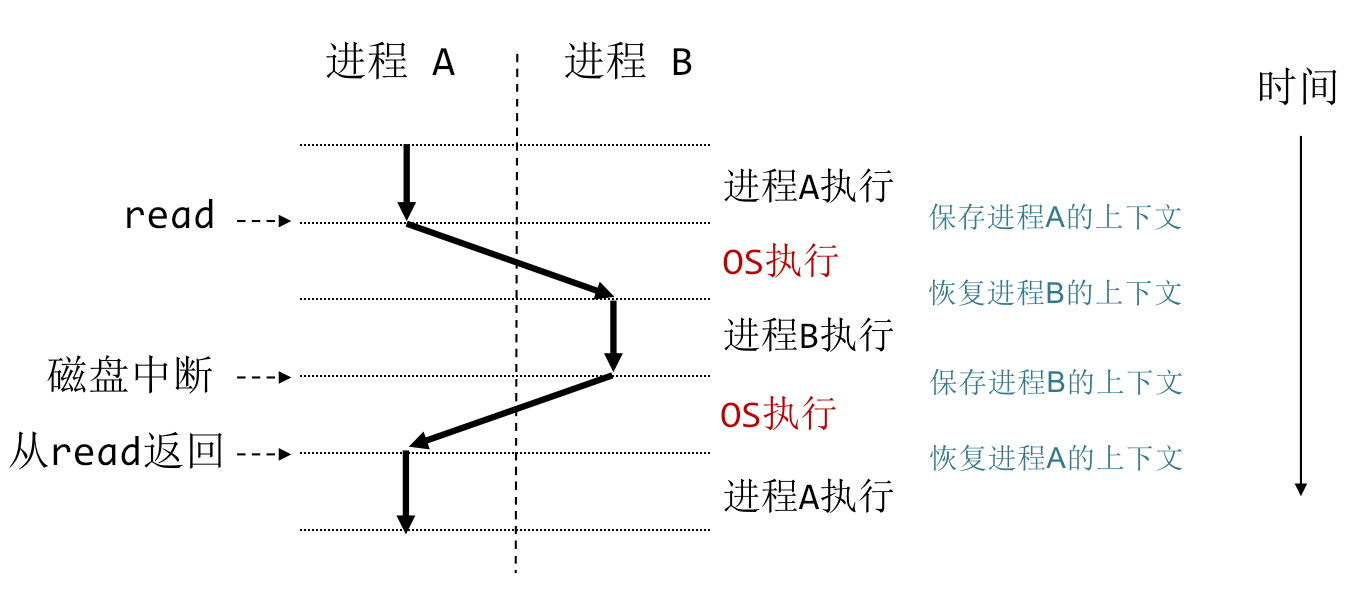
-
用户执行系统调用并进入内核,如read/sleep等会导致进程阻塞的系统调用。即使系统调用不阻塞执行,内核也可以决定执行上下文切换,而不是将控制权返回给调用进程。
常见的进程相关的接口
获取进程ID
- 进程 ID:每个进程都有唯一的正数PID
- Getpid():返回调用进程的PID
- Getppid():返回调用进程父进程的PID(父进程:创建该进程的进程)
getpid和getppid函数返回pid_t类型的int值。pid_t在Linux系统中,types.h文件中定义为int。
1 | |
Exit & Fork函数
1 | |
exit函数没有返回值,终止进程并带上一个status状态。
1 | |
父进程调用fork函数创建新的子进程。返回值:子进程为 0,父进程为子进程 PID,出错为 -1 。
fork函数在父进程中调用一次,在父进程和子进程中返回两次,返回值提供了唯一明确地区分父进程和子进程执行的方法。
使用事例:
1 | |
Execve函数
1 | |
filename:可执行文件名;argv:参数列表,envp:环境变量列表
execve 只调用一次,且永远不会返回。仅仅在运行报错的时候(如找不到filename标识的文件),才返回调用程序。
Linux下的僵尸进程
进程终止后,内核不会立刻销毁该进程,该进程不再运行,但仍然占用内存资源。进程以终止态存在,等待父进程回收。当父进程回收终止的子进程时,内核把子进程的exit状态传递给父进程,内核移除子进程,此时子进程才被真正回收。
终止状态下还未被回收的进程就是僵尸进程。如果父进程在自己终止前没有回收僵尸子进程,内核会安排init进程回收这些子进程。init进程的PID为1,在系统初始化时由内核创建。
为了解决这个问题,引入了进程等待的方法,可以通过进程等待的方式获取子进程的状态改变的信息,进而回收子进程占用的资源。此外通过进程等待的方式父进程也能了解到子进程完成的工作结果及是否正常退出。
进程等待实现方法:进程等待主要是通过使用系统调用接口waitpid函数来实现。通过给在父进程中使用waitpid函数来接收子进程状态改变的信息,进而实现对子进程的信息手机,资源回收等。
1 | |
- pid>0:等待集合中只有pid子进程
- pid=-1:等待集合包括所有子进程
- 如果没有子进程:返回-1,errno = ECHILD
- 如果等待被中断:返回-1,errno = EINTR
- options=0
- 挂起调用进程,等待集合中任意子进程终止
- 如果等待集合中有子进程在函数调用前已经终止,立刻返回
- 返回值是导致函数返回的终止子进程pid,该终止子进程被内核回收
- options=WNOHANG:如果等待集合中没有终止子进程,立刻返回0
- options=WUNTRACED:除了返回终止子进程的信息外,还返回因信号而停止的子进程信息
- options=WNOHANG|WUNTRACED
- status:带回被回收子线程的exit状态
- status指针不为NULL
- status包含导致子进程进入终止状态的信息
- wait.h文件包含了若干宏定义,用于解释status
内存
虚拟内存
应用进程使用虚拟地址访问内存,所有应用进程的虚拟地址空间都是统一的(方便开发)。
CPU按照OS配置的规则把虚拟地址翻译成物理地址,翻译对于应用进程是不可见的(无需关心)。
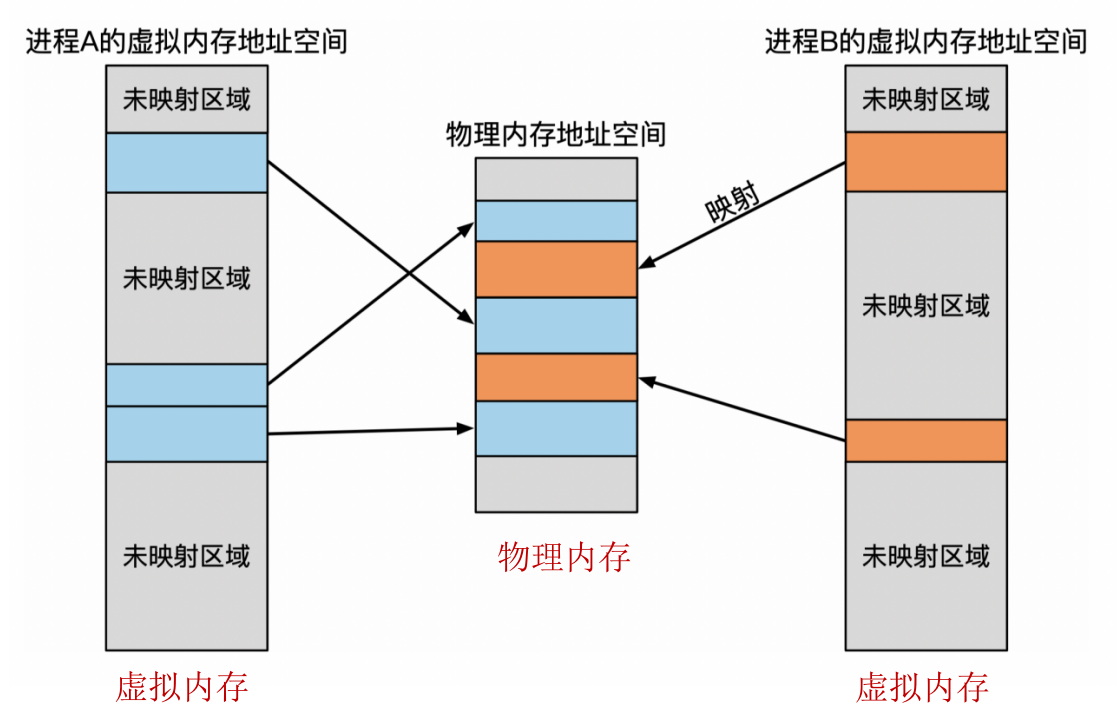

两个程序分配给 g_val 的地址相同,所以这个地址不可能是物理地址,而是相同的虚拟地址。
虚拟内存的优势:
- 提高内存资源利用率,操作系统按需把进程虚拟地址映射到物理地址
- 突破物理内存的容量限制,操作系统可以将部分虚拟内存区域数据暂存到磁盘上
文件
Unix 文件
Unix文件是一串字节序列:B0,B1,…, Bk,…,Bm 。所有IO设备都被抽象成文件,如网络设备、硬盘、终端等。Unix提供一个基于文件的底层应用接口,即 Unix IO。所有输入/输出都是通过读/写文件完成。
-
普通文件(regular file):包含任意数据
从应用程序的角度来看有两种,文本文件:仅包含ASCII或Unicode字符,二进制文件:除文本文件以外的所有
从内核的角度来看,它们没有区别。 -
目录(directory)
由一组链接(links)构成,每个链接将一个文件名映射到一个文件(或目录)。目录相关指令:mkdir、ls、rmdir等。
每个目录至少有两个链接:.(dot):到文件夹本身的链接..(dot-dot):到上一层文件夹的链接
-
套接字(Socket):用于跨网络进程交互
其他文件类型包括:- 命名管道(named pipes)
- 符号连接(symbolic links)
- 字符/块设备(character/block devices)
打开文件
内核打开相关文件,并返回一个非负整数,作为文件标识符(file descriptor, fd)。fd代表该文件,用于之后对文件进行操作,内核跟踪记录每个进程的所有打开文件的信息。
对于每个打开文件,维护一个文件内偏移k,应用可以通过seek函数,显式改变当前文件内偏移k,应用只需要记录内核返回的文件标识符。
1 | |
关闭文件
内核操作:释放在文件打开时创建的数据结构,并把文件标识符返回到可用标识符池。
进程终止时的默认行为:内核关闭所有打开的文件,内核释放内存资源。
1 | |
读写文件
- 读操作:从文件中复制m>0个字节到内存中。
从当前文件的位置k开始, 并更新k+=m,如果从k开始到文件末尾的长度小于m,触发一个条件 end-of-file(EOF)。EOF可以被应用检测,但文件末尾实际上不存在EOF字符。 - 写操作:从内存中复制m>0个字节到文件中。
1 | |
读写示例:
1 | |
内存地址翻译
编译器假设应用运行时,会独占所有内存,且内存足够大。由CPU将虚拟地址翻译到物理地址,由操作系统来配置如何翻译。
分页机制
- 物理内存可以看成由连续字节组成的数组,每个字节都有唯一的物理地址;
- Memory Management Unit (MMU)按照规则将虚拟地址翻译成物理地址。
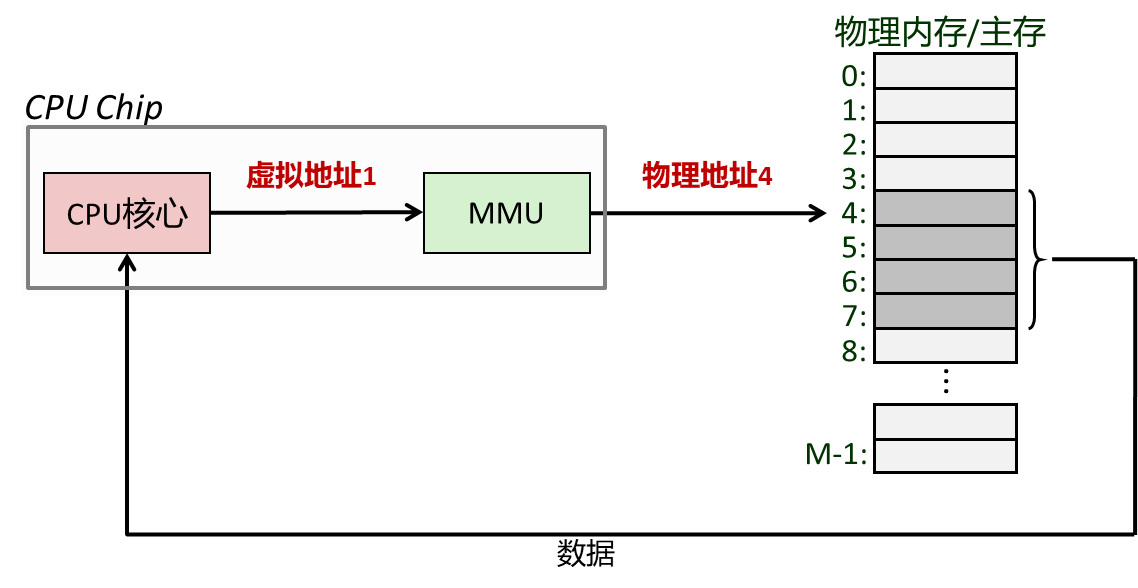
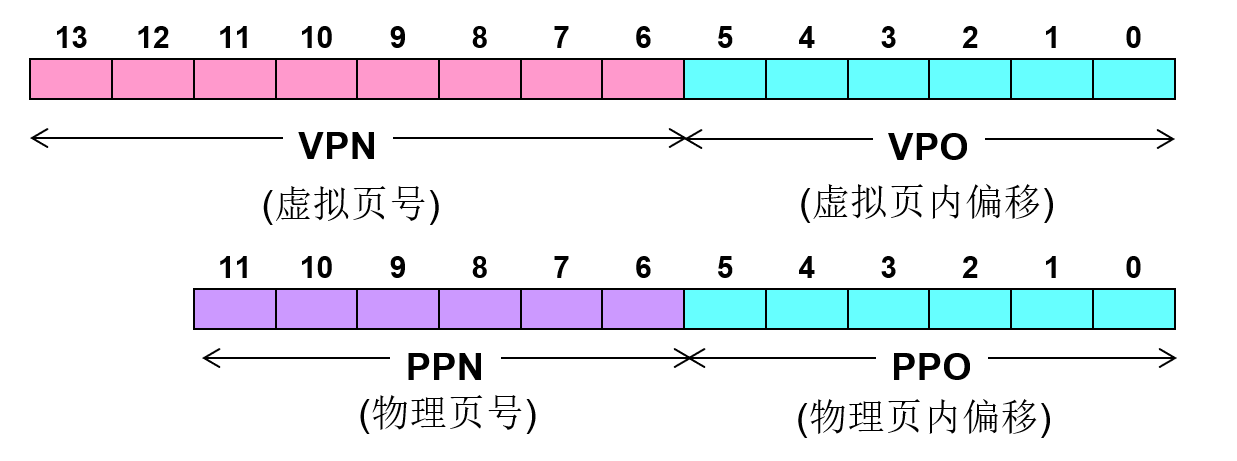
虚拟地址空间和物理内存划分成连续的、等长的虚拟页,虚拟页和物理页的页长相等。
虚拟地址分为:虚拟页号 + 页内偏移
使用页表记录虚拟页号到物理页号的映射。
- 特点:
- 物理内存离散分配,任意虚拟页可以映射到任意物理页,大大降低对物理内存连续性的要求;
- 主存资源易于管理,利用率更高。按照固定页大小分配物理内存,大大降低外部碎片和内部碎片。
内存地址翻译
PPO与VPO相等,根据页表查看VPN对应的PPN,即可将虚拟地址翻译为物理地址。
例子
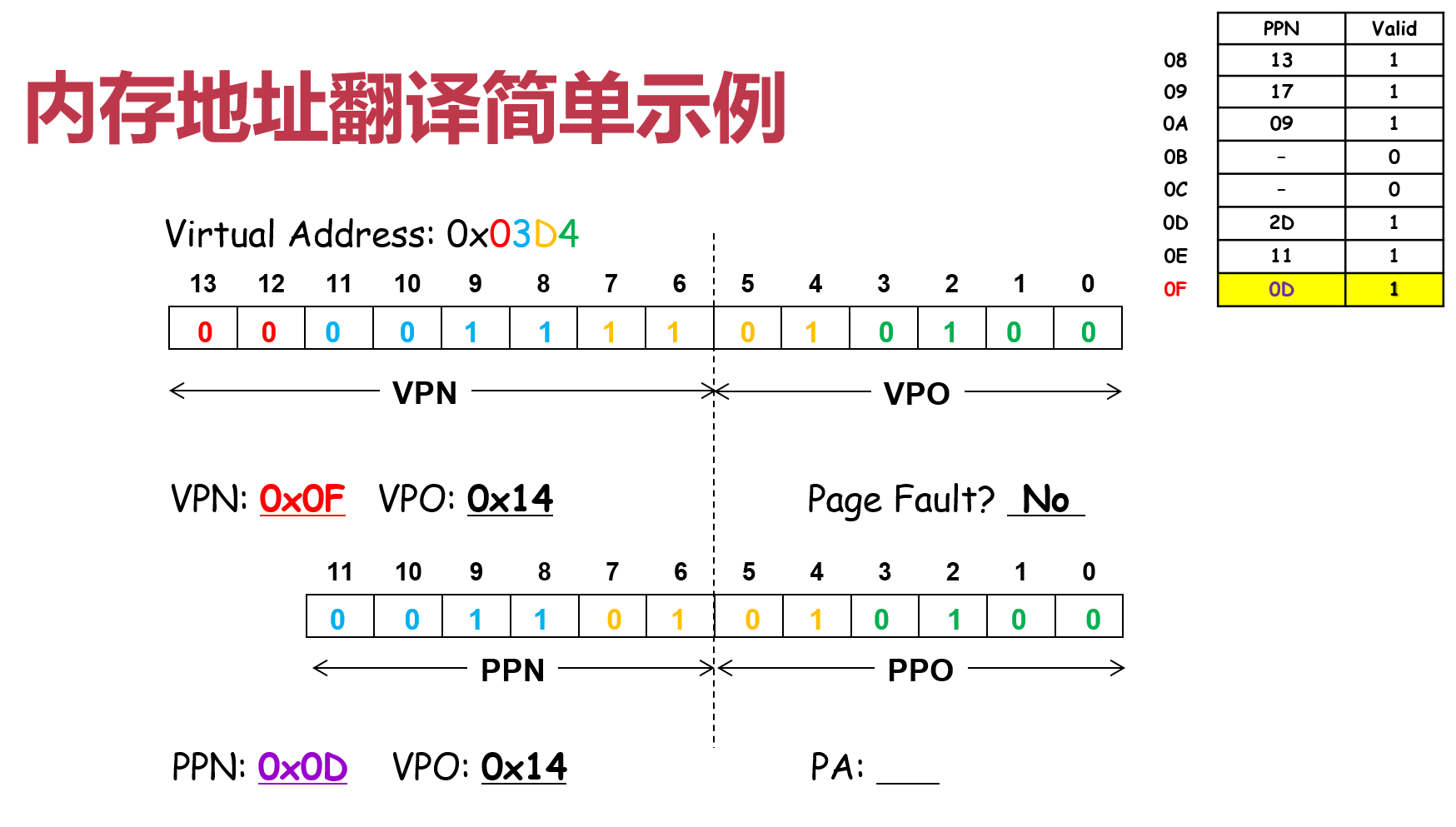
页大小为2^VPO位数,VPN为 0F,在页表中对应的PPN为0D。
单级页表问题和多级页表优点
假设64位的地址空间,页大小为4K,页表项为8字节,那么页表大小:
(不现实!)
多级页表能有效压缩页表的大小,若某个页表页中的某个页表项为空,那么其对应的下一级页表页便无需存在,应用程序的虚拟地址空间大部分都未分配。
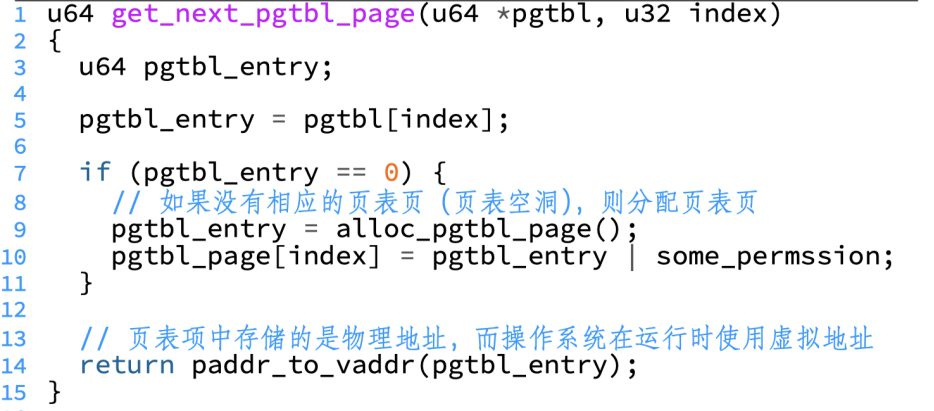
AARCH64体系结构下4级页表
硬件规定:
- 每个页表页占用一个 4K 的物理页,
- 每个页表项占用八个字节,所以每个页表页有 个页表项。
虚拟地址每一位的解析:
- 「63:48」16-bit:必须全是0或者全是1(软件用法:一般应用程序地址是0,内核地址是1)也意味着虚拟地址空间大小最大是2^48 Byte,即256TB。
- 「47:39」9-bit:0级页表索引
- 「38:30」9-bit:1级页表索引
- 「29:21」9-bit:2级页表索引
- 「20:12」9-bit:3级页表索引
- 「11:0」12-bit:页内偏移
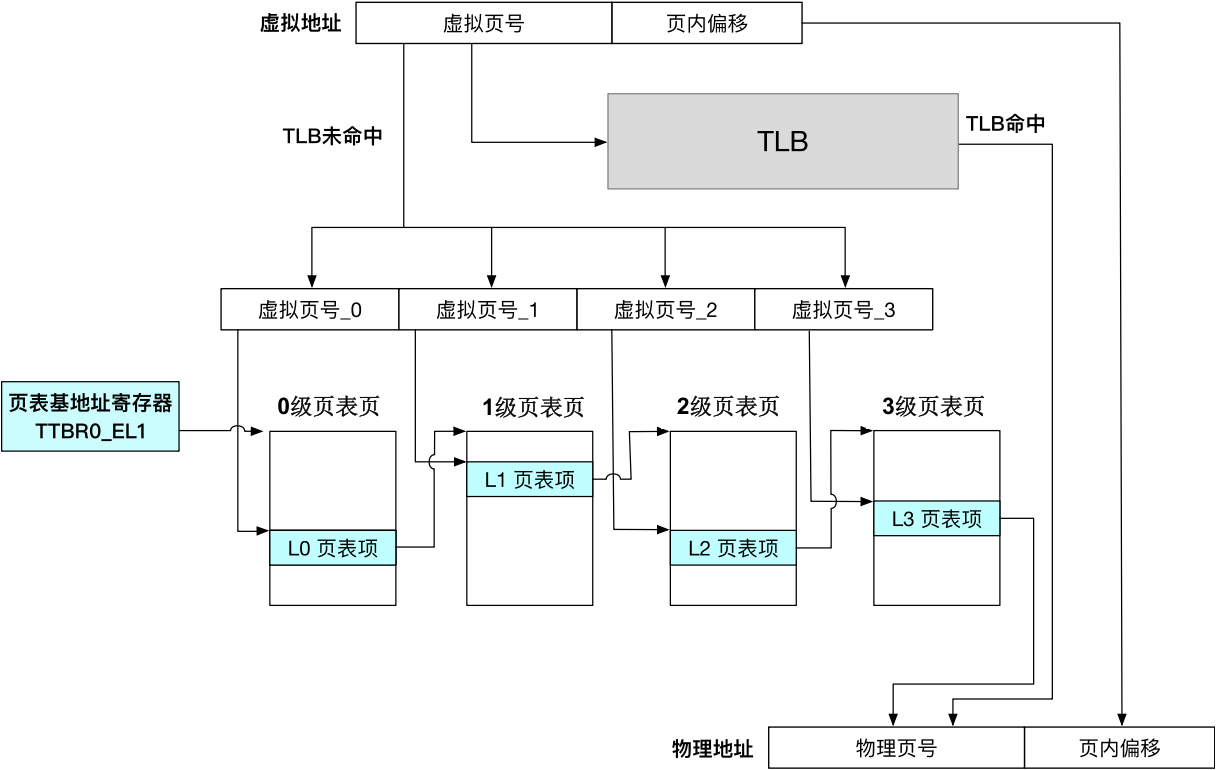
问:若页表共占用16K,能够翻译的虚拟地址范围是?
答:16K,说明0-3级页表各一个,能翻译 范围的地址范围。
问:在页表中填写虚拟地址 0-16M 的映射,则页表至少需要占用多少空间?
答:是上面问题的反过来,需要 个物理页,所以需要 个L3页,L0、L1、L2页各一个,共.
页表项
页表页
每级页表有若干离散的页表页,每个页表页占用一个物理页,第 0 级(顶层)页表有且仅有一个页表页。页表基地址寄存器存储的就是该页的物理地址,每个页表页中有 512 个页表项,每项为 8 个字节(64位),用于存储物理地址和权限。

- V(Valid):当访问时V=0,则触发缺页异常
- UXN(Unprivileged eXecute Never):用户态不可执行(例如栈)
- PXN(Privileged eXecute Never):内核态不可执行(防止内核执行用户代码)
- AF(Access Flag):当访问时,MMU标记该位
- AP(Access Permissions):
- DBM (Dirty Bit): 51位,ARMv8.1-TTHM特性支持
页表项与大页
多级页表中并非只有最后一级的页表项能够指向物理页,中间级的页表项也能够直接指向物理页,而不是只能指向下一级页 表页。当中间级的页表项直接指向物理页时,其指向的会是大页,顾名思义, 会比下一级页表项指向的物理页大小更大。
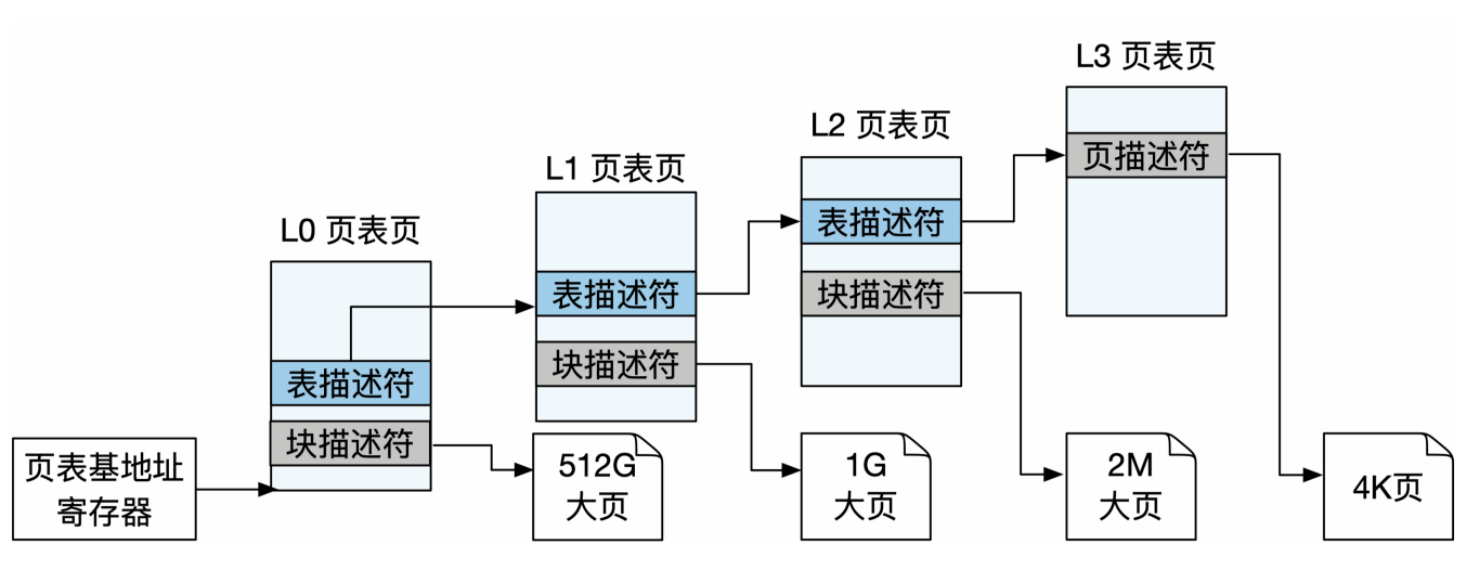
- 优点:减少TLB缓存项的使用,提高 TLB 命中率;减少页表的级数,提升遍历页表的效率;
- 缺点:未使用整个大页而造成物理内存资源浪费,增加管理内存的复杂度。
TLB:缓存页表项、地址翻译的加速器
多级页表不是完美的,它压缩页表大小,但增加了访存次数(逐级查询)。1次内存访问,变成了5次内存访问。
TLB 位于CPU内部,是页表的缓存。在地址翻译过程中,MMU首先查询TLB,TLB命中,则不再查询页表 (fast path);TLB未命中,再查询页表。
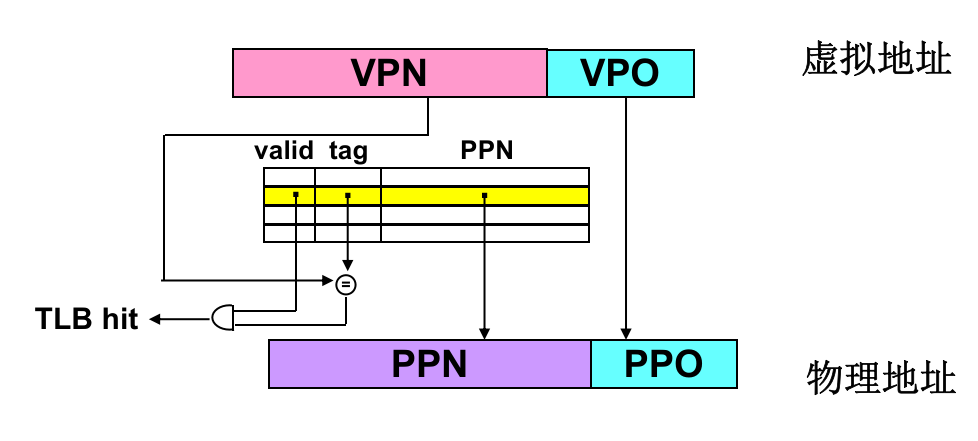
TLB 刷新
TLB 使用虚拟地址索引,当OS切换进程页表时需要全部刷新。AARCH64上内核和应用程序使用不同的页表,分别存在TTBR0_EL1和TTBR1_EL1中。所以使用的虚拟地址范围不同,系统调用过程不用切换。
操作系统管理页表映射
设置页表映射是操作系统的职责。TTBR0_EL1 和 TTBR1_EL1 分别指向内核和应用页表。
何时设置页表映射
- 操作系统自己使用的页表
- 在启动时填写
- 映射全部物理内存
- 虚拟地址 = 物理地址 + 固定偏移(直接映射,Direct Mapping)
- 思考:为什么需要直接映射?答:因为简单好计算。
- 应用进程的页表设置时间?
立即映射
即创建进程时,OS按照虚拟内存区域填写进程页表。具体步骤:
- 分配物理页(alloc_page),
- 把应用代码/数据从磁盘加载到物理页中,
- 添加虚拟页到物理页的映射(add_mapping),
- 未加载完毕,回到步骤-1。
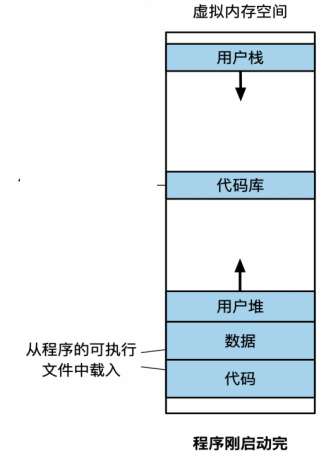
弊端:只玩一关,加载100关。
- 物理内存资源浪费
- 非必要时延
对内核来说:已映射的地址不一定正在使用(需要通过kmalloc才能用),正在使用的地址通常已映射(例外:vmalloc);
对应用来说:正在使用的地址不一定已映射(on-demand paging),已映射的地址一定正在使用(否则不会被映射)。
同一个物理地址可以有多个虚拟地址。如应用任一已映射的物理地址,在内核的直接映射下也有一个虚拟地址。
延迟映射
操作系统按进程实际需要分配物理页和填写页表,避免分配的物理页实际不被用到的情况。
主要思路:解耦虚拟内存分配与物理内存分配。
- 先记录下为进程分配的虚拟内存区域;
- 当进程实际访问某个虚拟页时,CPU 会触发缺页异常;
- 操作系统在缺页异常处理函数中添加映射。
复习:


V(Valid):当MMU查询页表项时,若V=0,则触发缺页异常。
记录为进程分配的虚拟内存
在Linux中对应 vm_area_struct(VMA)结构体,在ChCore-Lab中对应 vmregion(vmr)结构体。

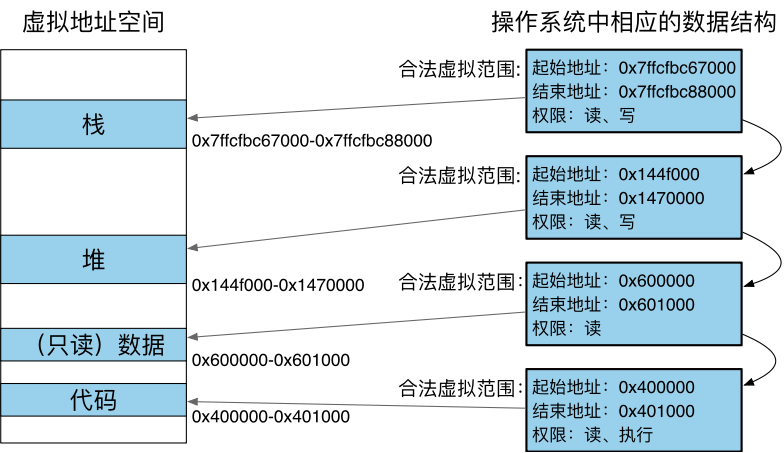
如何添加 VMA
- OS在创建进程时分配。
数据、代码(对应ELF文件的数据、代码段)栈(初始无内容) - 进程运行时添加。
堆、栈;mmap/munmap(分配内存buffer,加载新的代码库)
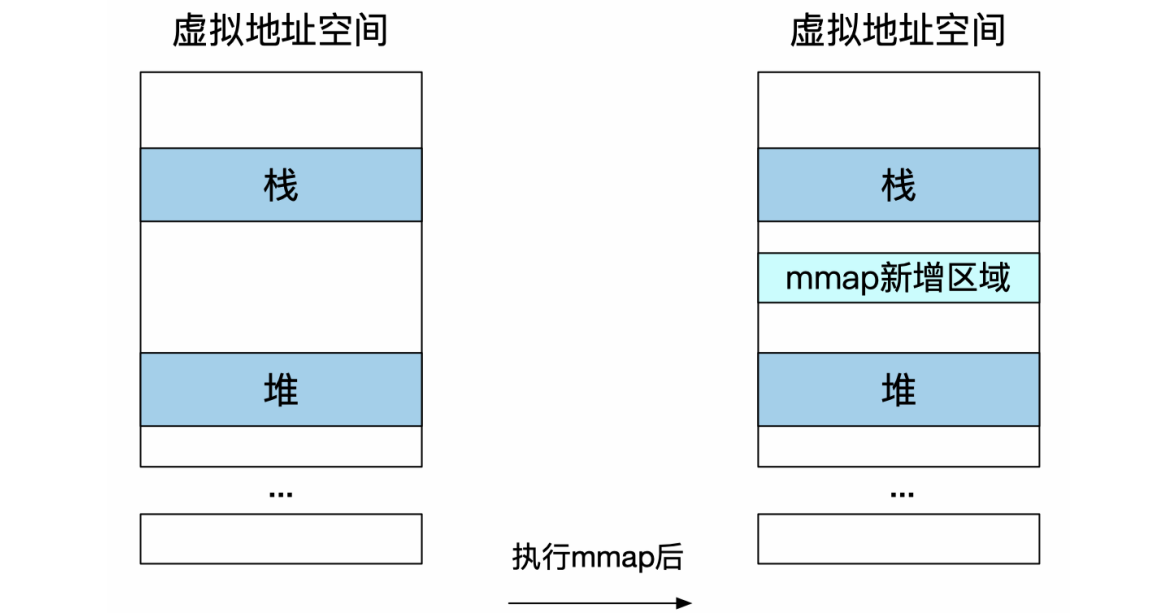
MMAP
通常用于把一个文件(或一部分)映射到内存。
1 | |
也可以不映射任何文件,仅仅新建虚拟内存区域(匿名映射)。
例如:
1 | |
执行 mmap 后,系统的变化如下图:
判断缺页异常的合法性
缺页异常(page fault)
- AARCH64:触发(通用的)同步异常(8);
- 根据ESR信息判断是否为缺页异常,访问的虚拟地址存放在FAR_EL1;
- FAR_EL1中的值不落在VMA区域内,则为非法;反之,则分配物理页,并在页表中添加映射。
立即映射 vs. 延迟映射
- 优势:节约内存资源
劣势:缺页异常导致访问延迟增加 - 如何取得平衡?
应用程序访存具有时空局部性(Locality)。在缺页异常处理函数中采用预先映射的策略,既节约内存又能减少缺页异常次数。
分配物理页的简单实现
操作系统用位图记录物理页是否空闲,0:空闲;1:已分配。
操作系统在进程结构体中保存页表基地址。


paddr_to_vaddr如何实现?
答:直接映射。1
int paddr_to_vaddr(int pddr){return pddr + offset;}- 参数
pgtbl是虚拟地址还是物理地址?
虚拟内存的扩展功能
共享内存、写时拷贝(copy-on-write)
大页的使用
- 好处:减少TLB缓存项的使用,提高 TLB 命中率;减少页表的级数,提升遍历页表的效率;
- 弊端:未使用整个大页而造成物理内存资源浪费,增加管理内存的复杂度。
TCR_EL1可以选择不同的最小页面大小- 三种配置:4K、16K、64K
- 4K + 大页:2M/1G
- 16K + 大页:32M(问:为什么是32M?)(只有L2页表项支持大页)
答:一个页表项为 bits,那么 大页可以放下 个页表项,所以大页可以放下这么多小页,大页大小为 。 - 64K + 大页:512M
物理内存管理
OS职责:分配物理内存资源
- 用户态应用程序触发on-demand paging(延迟映射)时,此时内核需要分配物理内存页,映射到对应的虚拟页;
- 内核自己申请内存并使用时,如用于内核自身的数据结构,通常通过kmalloc()完成;
- 发生换页(swapping)时,通过磁盘来扩展物理内存的容量;
- 内核申请用于设备的DMA内存时,DMA内存通常需要连续的物理页。
场景1:应用触发 on-demand paging
应用调用malloc后,返回的虚拟地址属于某个VMA,但虚拟地址对应的页表项的valid bit可能为0,当第一次访问新分配的虚拟地址时,CPU会触发 page-fault。
操作系统需要做:
- 找到一块空闲的物理内存页; ← 物理内存管理(页粒度)
- 修改页表,将该物理页映射到触发
page-fault的虚地址所在虚拟页; - 恢复应用,重复执行触发
page-fault的那行代码。
物理内存分配器的指标
资源利用率、分配性能。
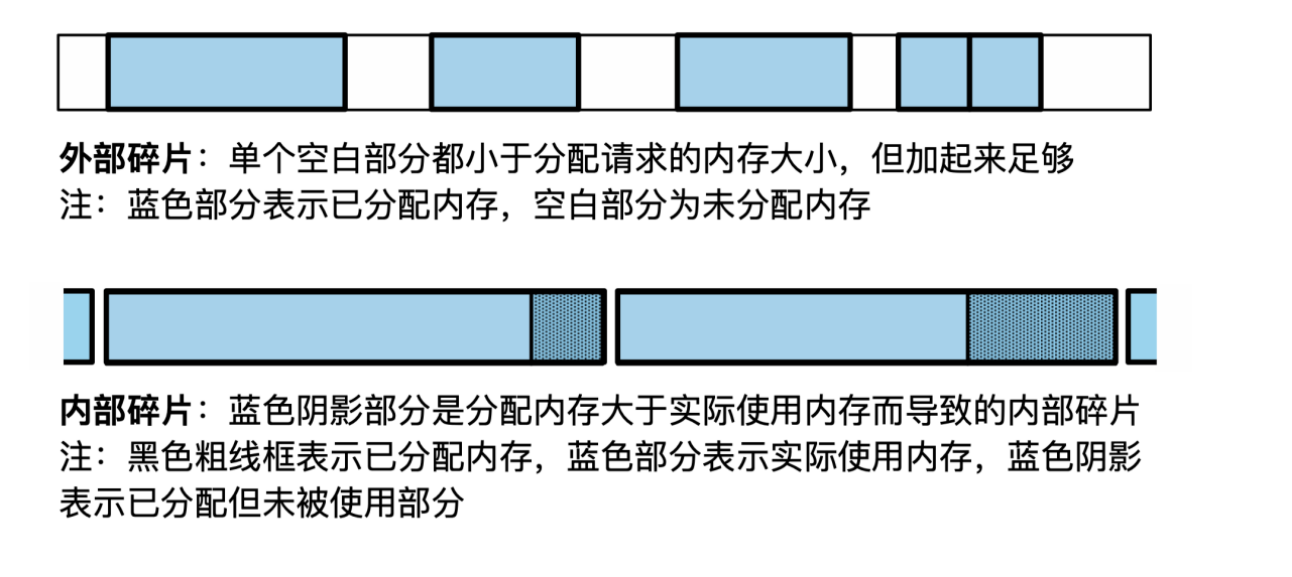
资源利用率:外部碎片与内部碎片。
解决方式:伙伴系统(buddy system)
分裂与合并(避免外部碎片)。
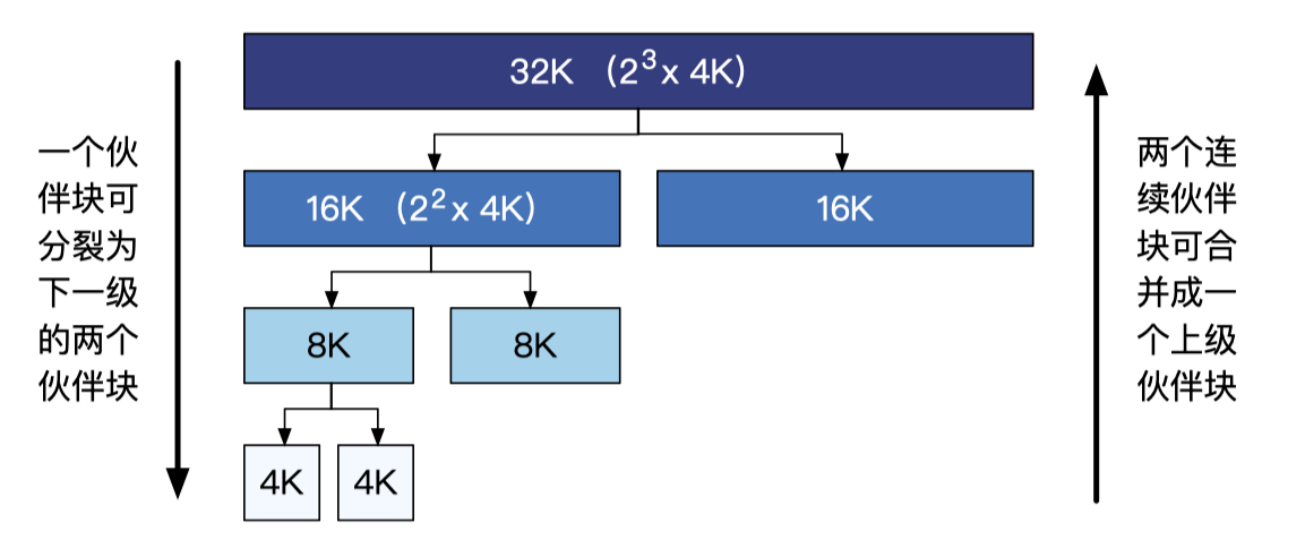
当一个请求需要分配 m 个物理页时,伙伴系统将寻找一个大小合适的块, 该块包含 2n个物理页,且满足 2n−1< m ⩽ 2n。
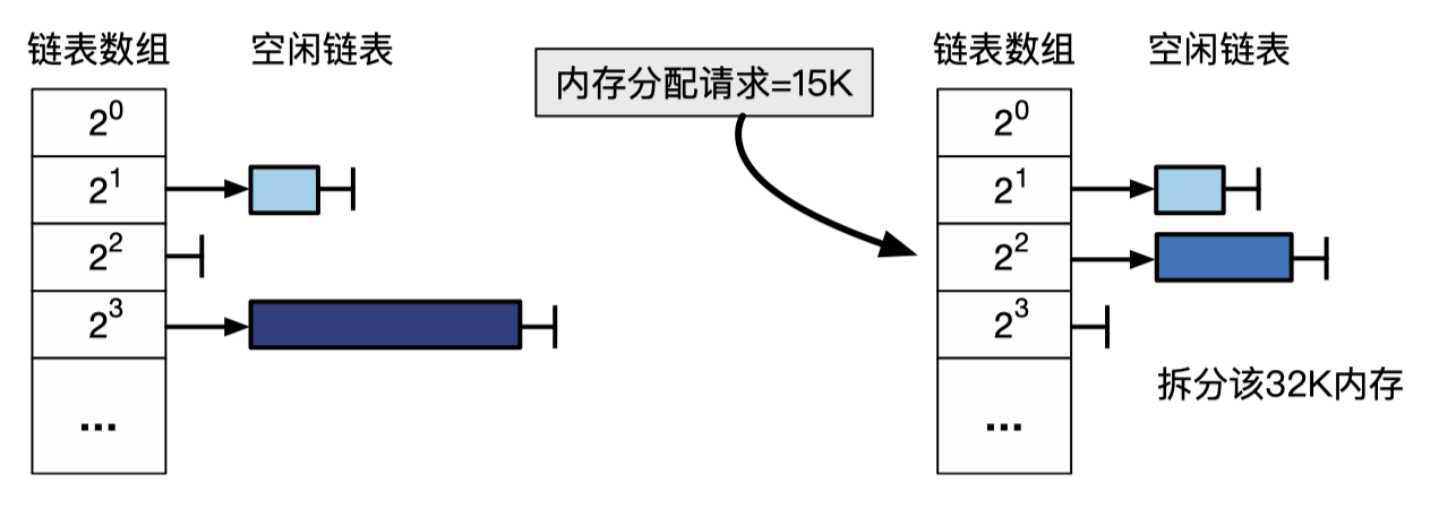
看上图,用分配 15K 举个例子,合适的大小是 16K,因此首先查找第2条(2^2)空闲链表,如果链表不为空, 则可以直接从链表头取出空闲块进行分配。但是,在这个例子中,该链表为空,分配器就会依次向存储更大块的链表去查找。由于第 3 条链表不为空,分配器就从该链表头取出空闲块(32K)进行分裂操作,从而获得两个 16K 大小的 块,将其中一个用于服务请求(这里不再需要继续向下分裂),另一个依然作 为空闲块插入到第 2 条链表中。若再接收到一个大小为 8K 的分配请求,分配器则会直接从第 1 条链表中取出空闲块服务请求。之后,继续接收到一个大小为 4K 的分配请求,分配器则会取出第 2 条链表中大小为 16K 的空闲块进行连续分裂,从而服务请求。读者可以思考并画出此时空闲链表数组的内容。释 放块的过程与分配块的过程相反,分配器首先找到被释放的块的伙伴块,如果伙伴块处于非空闲状态,则将被释放的块直接插入对应大小的空闲链表中,即完成释放;如果伙伴块处于空闲状态,则将它们两个块进行合并,当成一个完整的块释放,并重复该过程。
合并过程如何定位伙伴块
互为伙伴的两个块的物理地址仅有一位不同,通过块的大小决定是哪一位。
例如:块A(0-8K)和块B(8-16K)互为伙伴块,且块A和B的物理地址分别是 0x0 和 0x2000,它们仅有第13位不同,所以块大小是8K()。
资源利用率、分配性能
- 外部碎片程度降低(思考:是否不再出现外部碎片?)内部碎片依然存在:如请求9KB,分配16KB(4个页)。
答:不能避免不再出现外部碎片。 - 分配、合并的时间复杂度:最差,是常数时间。
SLAB/SLUB/SLOB:细粒度内存管理
场景-2:内核运行中需要进行动态内存分配
内核自身用到的数据结构,为每个进程创建的process,VMA等数据结构。用时分配,用完释放,类似用户态的 malloc,且数据结构大小往往小于页粒度。
SLAB:建立在伙伴系统之上的分配器
可以快速分配小内存对象,内核中的数据结构大小远小于4K(例如VMA),后续以主流的SLUB为例讲解。
观察发现操作系统频繁分配的对象大小相对比较固定。因此从伙伴系统获得大块内存(名为slab),对每份大块内存进一步细分成固定大小的小块内存进行管理。块的大小通常是 2n 个字节(一般来说,3 ⩽ n < 12),也可为特定数据结构增加特殊大小的块,从而减小内部碎片
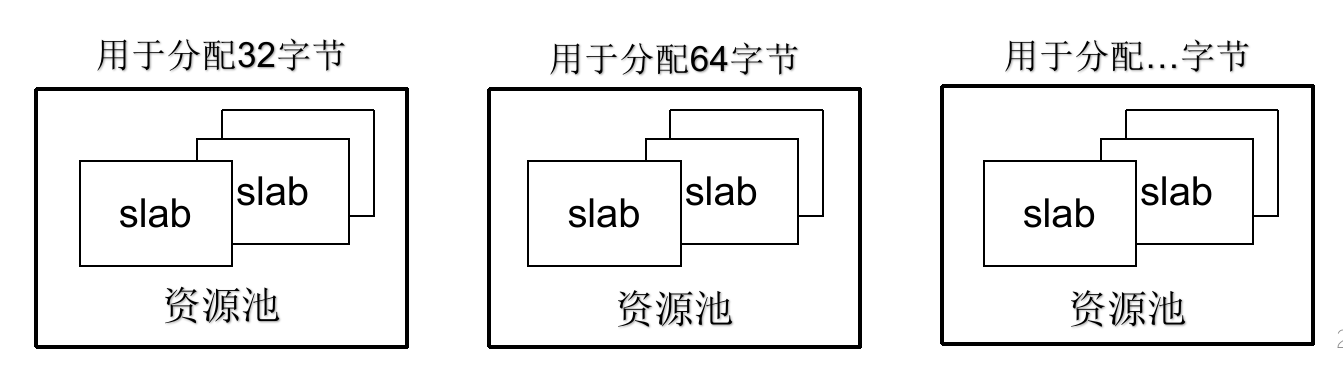
SLUB 设计
只分配固定大小块。对于每个固定块大小,SLUB 分配器都会使用独立的内存资源池进行分配,采用 best fit 定位资源池。
-
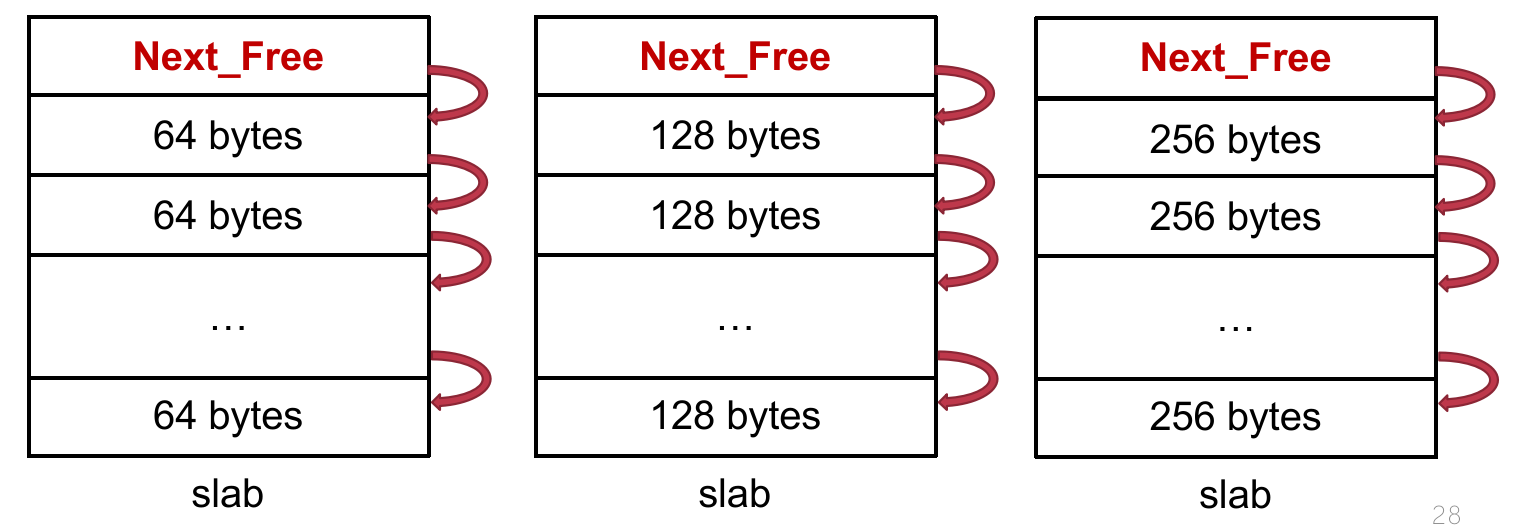
初始化资源池:把从伙伴系统得到的连续物理页划分成若干等份(slot)。
-
分配与释放:
- 分配N字节:定位到大小最合适的资源池(假设只有一个slab),从slab中取走
Next_Free指向的第一个slot; - 释放:将
Next_Free指针指向待释放内存(slot)。
- 分配N字节:定位到大小最合适的资源池(假设只有一个slab),从slab中取走
-
释放具体流程:根据待释放内存地址计算slab起始地址
ADDR & ~(SLAB_SIZE-1)
上述方法在kfree(addr)接口下可行吗?
答:没有size信息,无法判断addr是被slab分配的,还是伙伴系统分配的。
解决方式:在物理页结构体中记录所属slab信息。 -
新增slab:当某个资源池(例如64字节对应的资源池)中的slab已经分配完怎么办?再从伙伴系统分配一个slab。
-
资源池内组织多个slab:引入两个指针(current,partial)。
- Current指向一个slab,并从其中分配;当Current slab全满,则从Partial链表中取出一个放入Current;
- 释放后,若某个slab不再全满,则加入partial;释放后,若某个slab全空则可还给伙伴系统。
突破物理内存容量限制
换页机制(Swapping)
用磁盘作为物理内存的补充,且对上层应用透明,应用对虚拟内存的使用,不受物理内存大小限制。
磁盘上划分专门的Swap分区,或专门的Swap文件,在处理缺页异常时,触发物理内存页的换入换出。
如何判断缺页异常是由于换页引起的?
导致缺页异常的三种可能:
- 访问非法虚拟地址
- 按需分配(尚未分配真正的物理页)
- 内存页数据被换出到磁盘上
利用VMA区分是否为合法虚拟地址(合法缺页异常)。利用页表项内容区分是按需分配还是需要换入。
何时进行换出操作
- 策略A:当用完所有物理页后,再按需换出。当内存资源紧张时,大部分物理页分配操作都需要触发换出,造成分配时延高。
- 策略B:设立阈值,在空闲的物理页数量低于阈值时,操作系统择机(如系统空闲时) 换出部分页,直到空闲页数量超过阈值。
换页机制的代价
-
优势:突破物理内存容量限制
-
劣势:缺页异常+磁盘操作导致访问延迟增加
-
策略:预取机制 (Prefetching)
预测接卸来进程要使用的页,提前换入;在缺页异常处理函数中,根据应用程序访存具有的空间本地性进行预取。
如何选择换出的页
- 理想策略:优先换出未来最长时间内不会再访问的页面
- FIFO策略:操作系统维护一个队列用于记录换入内存的物理页号,每换入一个物理页就把其页号加到队尾。
Belady异常:使用FIFO策略,物理资源增加反而导致了性能下降。 - Second Chance策略:FIFO 策略的一种改进版本:为每一个物理页号维护一个访问标志位。如果访问的页面号已经处在队列中,则置上其访问标志位。
换页时查看队头:1)无标志则换出;2)有标志则去除并放入队尾,继续寻找。 - 时钟算法:
总结:物理内存管理
进程
回顾:处理器上下文,分时复用cpu
进程是计算机程序运行时的抽象。静态部分有程序运行需要的代码和数据,动态部分有程序运行期间的状态(程序计数器、堆、栈……)。
进程具有独立的虚拟地址空间。每个进程都具有“独占全部内存”的假象,内核中同样包含内核栈和内核代码、数据。
进程的表示:PCB
每个进程都对应一个元数据,称为“进程控制块”PCB。进程控制块存储在内核态(为什么?)
答:进程控制块存储在内核态,因为它由内核管理,不应被用户态的程序访问。
进程控制块里至少应该保存哪些信息?
- 独立的虚拟地址空间
- 独立的处理器上下文
- 内核栈
内核栈和用户栈
应用为什么需要“又一个栈”(内核栈)?
答:进程在内核中依然需要执行代码,有读写临时数据的需求;进程在用户态和内核态的数据应该相互隔离,增强安全性。
AArch64实现:两个栈指针寄存器
SP_EL1,SP_EL0- 当进程进入内核后,自动完成栈寄存器切换
- x86只有一个栈寄存器,需要保存恢复
进程的创建
创建进程就是初始化进程的内容。
用户视角:代码、数据、堆栈
内核视角:PCB、虚拟地址空间、上下文、内核栈
进程的创建(1):PCB初始化
- 分配PCB本身的数据结构
- 初始化PCB:虚拟内存,创建及初始化vmspace数据结构;分配一个物理页,作为顶级页表。
- 内核栈:分配物理页,作为进程内核栈
思考:处理器上下文初始化?在之后(应用运行前)才会初始化。

进程的创建(2):可执行文件加载
以 ELF 格式为例,从程序头部表可以获取需要的段所在位置。通常只有代码段和数据段需要被加载(loadable),加载即从ELF文件中映射到虚拟地址空间的过程。
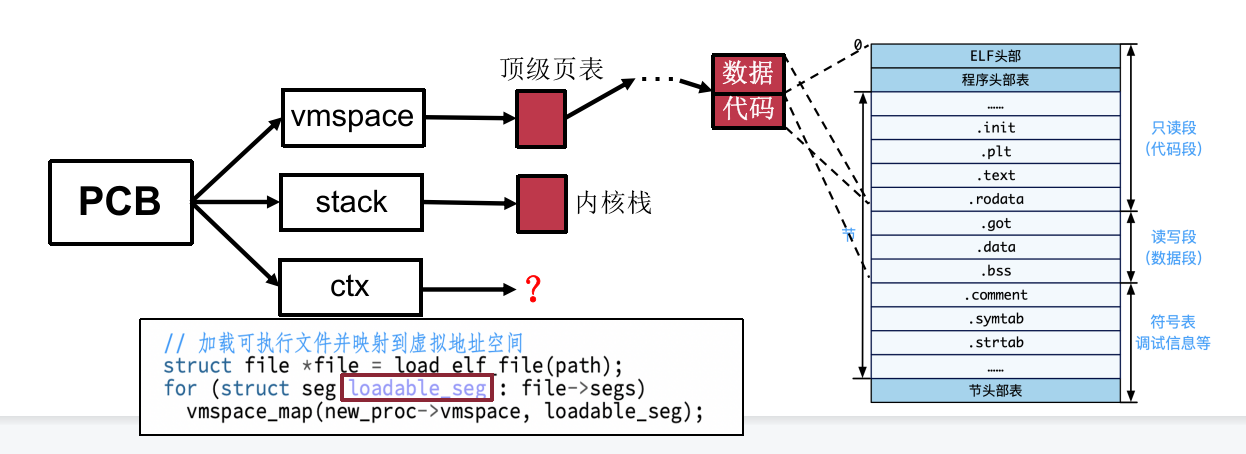
进程的创建(3):准备运行环境
在返回用户态运行前,还需为进程准备运行所需的环境,分配用户栈(分配物理内存并映射到虚拟地址空间)。
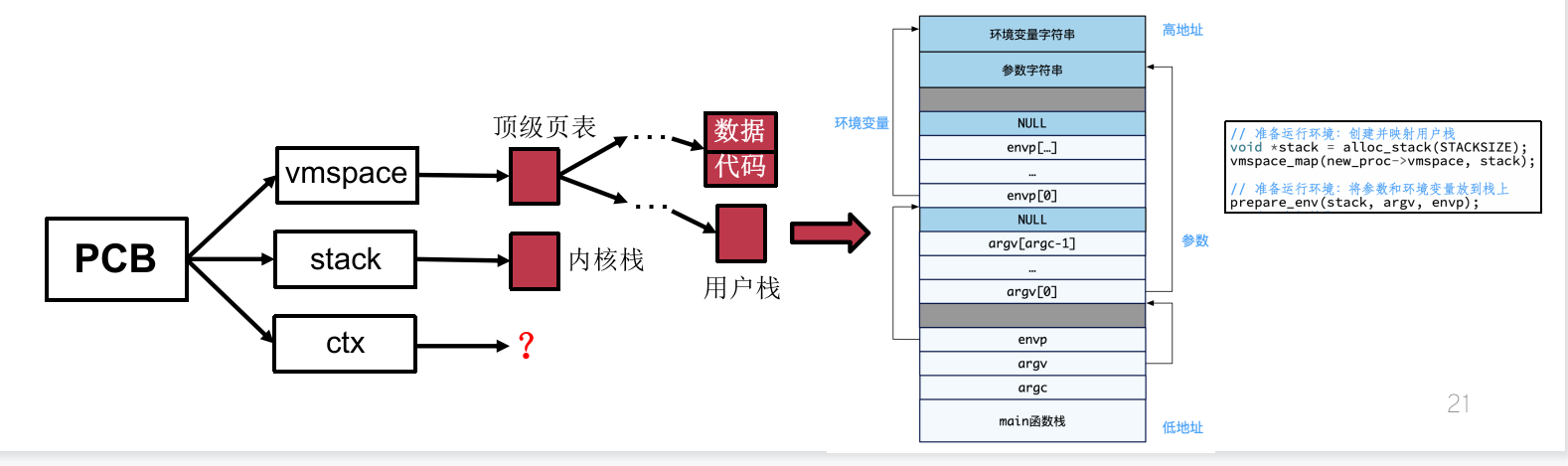
进程的创建(4):处理器上下文初始化
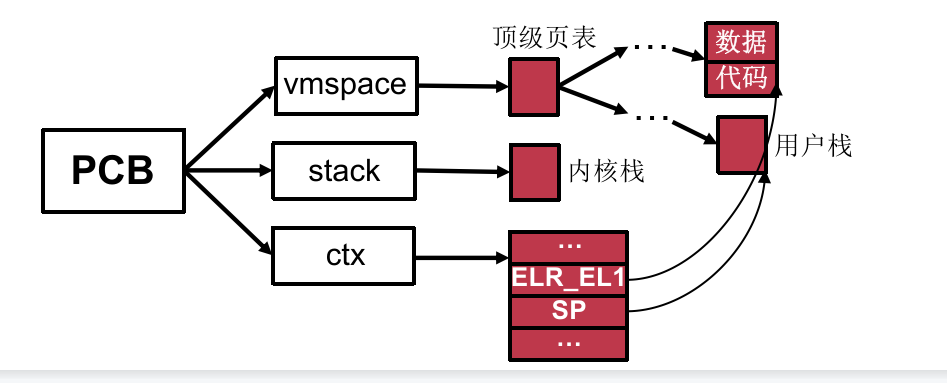
为什么直到最后才初始化处理器上下文?因为其包含的内容直到前序操作完成才确定。
SP:用户栈分配后才确定地址
PC(保存在ELR_EL1):加载ELF后才知道入口所在地址
大部分寄存器初始值可直接赋为0。

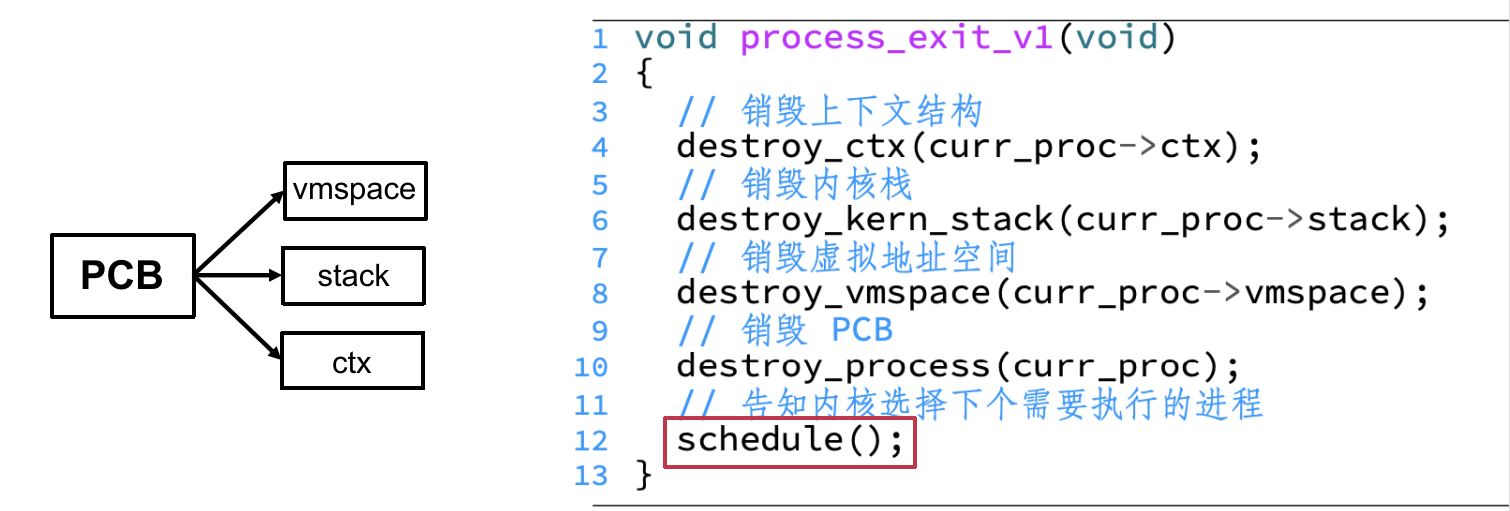
进程的退出与等待
需要一个系统调用使进程显式退出(exit)。但使用return更为常规,此时可由libc的代码调用process_exit,退出进程。
实现:销毁PCB及其中保存的所有内容,并告知内核选择其他进程执行(细节之后介绍)。
改进代码实现:
- 为了使shell等待,直到命令退出,引入新系统调用:进程等待
process_waitpid。 - 为了使shell知道应该等待哪个进程,为每个进程引入进程标识符(id)。
- 为进程加入
退出状态支持,如果进程已设置为退出,则记录其退出状态并回收。这将进程资源的回收操作从exit移到了waitpid。 - 为了实现只有创建某进程的程序才能监控它,引入父(创建者)子(被创建者)进程概念。进程之间的创建关系构建了一棵进程树,第一个进程(树根)通常由内核主动创建。
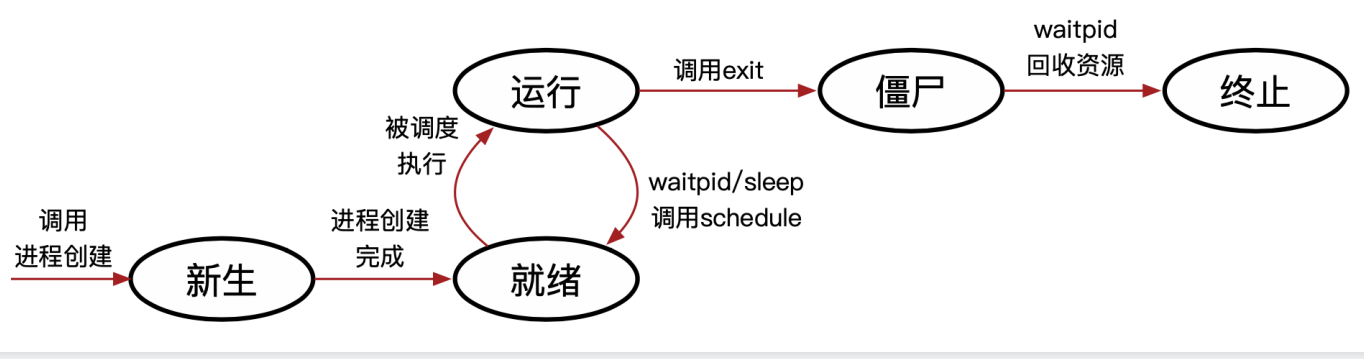
进程的状态
- 新生(new):刚调用process_create
- 就绪(ready):随时准备执行(但暂时没有执行)
- 运行(running):正在执行
- 僵尸(zombie):退出但未回收
- 终止(terminated):退出且被回收
调度
调度的目的:选出下一个可以执行的进程,可以执行 = 就绪(ready)。

案例分析:LINUX进程创建
经典创建方法:fork()。语义:为调用进程创建一个一模一样的新进程,调用进程为父进程,新进程为子进程,接口简单,无需任何参数。
fork后的两个进程均为独立进程,拥有不同的进程id,可以并行执行,互不干扰(除非使用特定的接口)
。父进程和子进程会共享部分数据结构(内存、文件等)。
为了“一模一样”,将父进程的PCB拷贝一份,包括PCB、内核栈、处理器上下文(假设PCB结构为第一版),实现比较简单。
fork 优缺点分析
- fork的优点
接口非常简洁,(过去)实现简单;将进程“创建”和“执行”(exec)解耦,提高了灵活度。 - fork的缺点
- 创建拷贝的复杂度与PCB复杂度相关(如今越来越复杂)
- 完全拷贝过于粗暴(不如clone)
- 性能差、可扩展性差(不如vfork和spawn)
- 不可组合性 (例如:fork() + pthread())
进程切换
进程切换基本步骤
处理器上下文 vs. 进程上下文
-
处理器上下文:用于保存切换时的寄存器状态(硬件),在每个PCB中均有保存;
-
进程上下文:表示目前操作系统正以哪个进程的身份运行(软件),通常使用一个指向PCB的全局指针表示(代码中的curr_proc)。
-
进程切换节点:所有调用schedule()的地方
告知内核选择下一个执行的进程,也就涉及到了进程的切换。
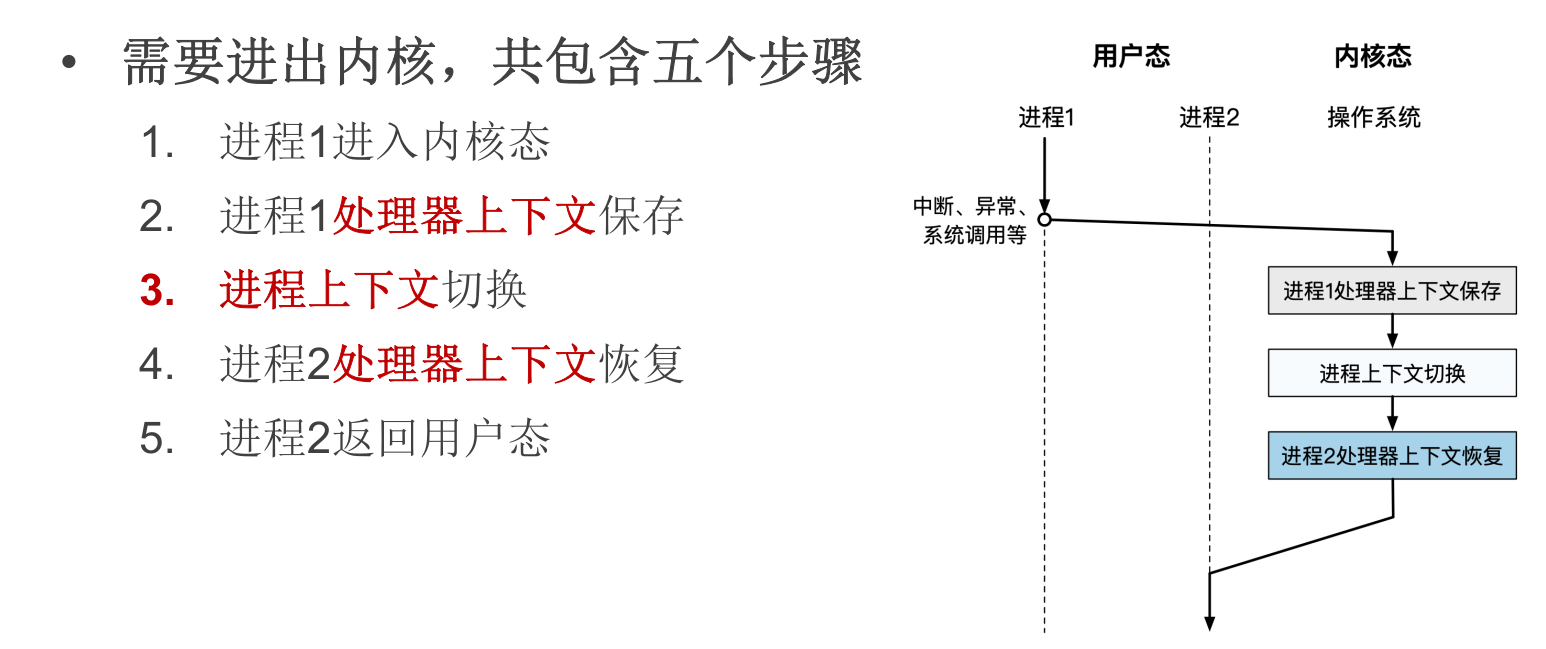
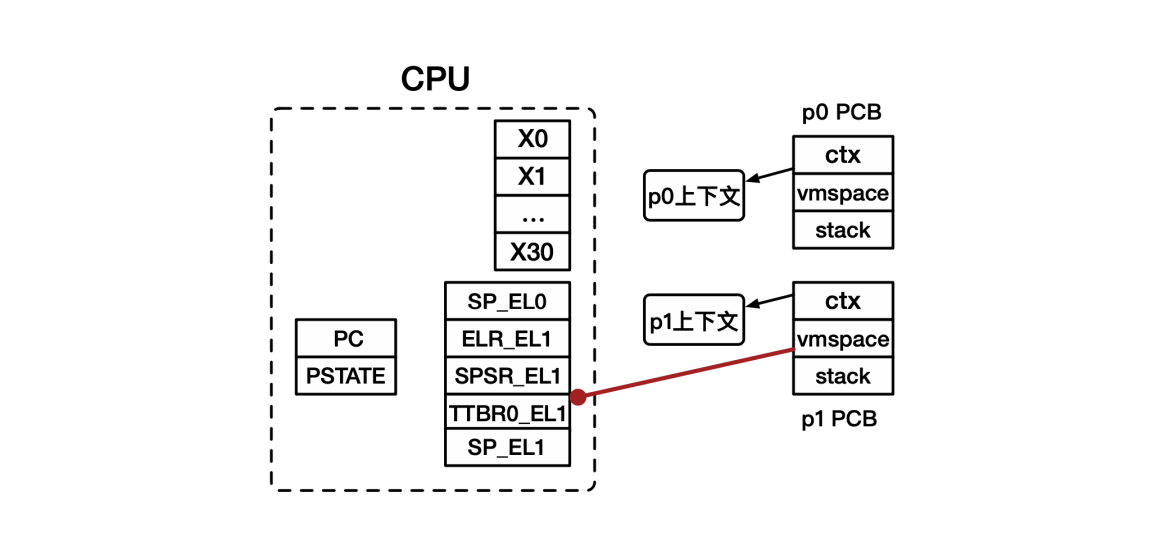
进程切换全过程
- p0进入内核态,由硬件完成部分寄存器保存:PC和PSTATE分别自动保存到ELR_EL1和SPSR_EL1。
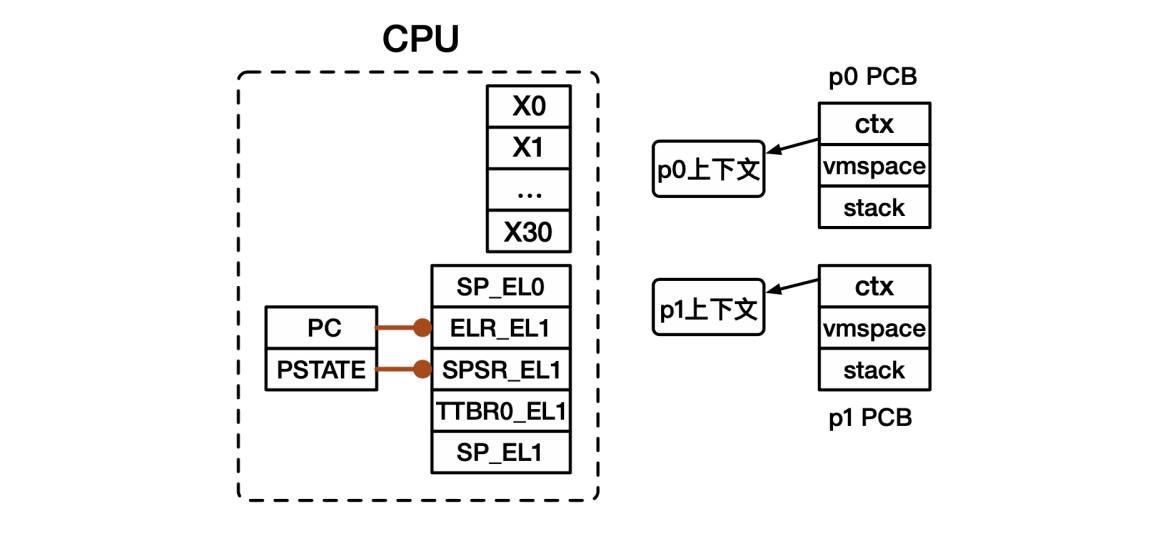
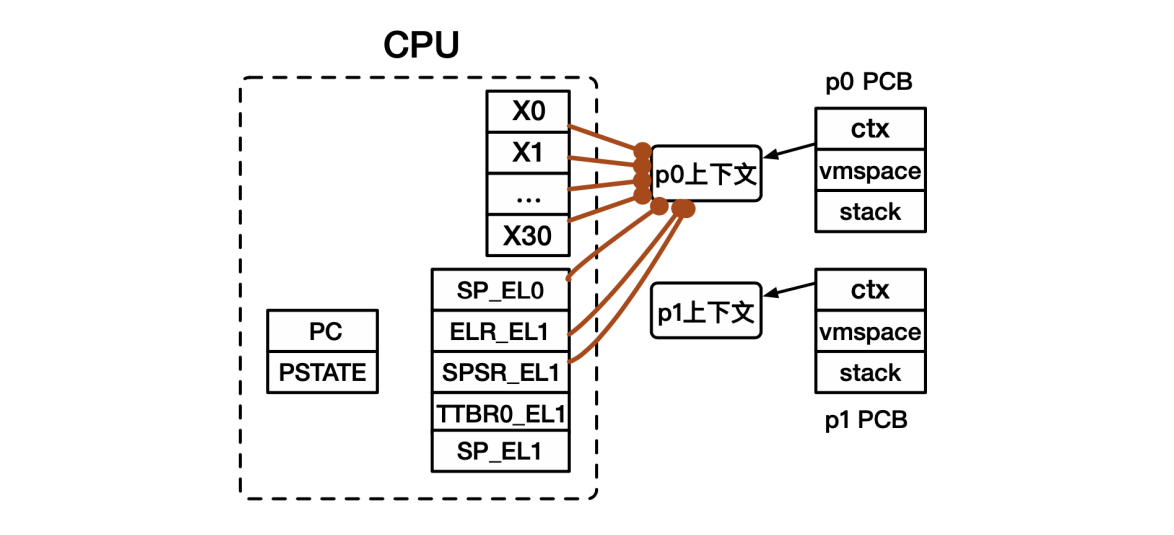
- p0处理器上下文保存:将处理器中的寄存器值保存到处理器上下文对应的位置。
- 虚拟地址空间切换:设置页表相关寄存器(TTBR0_EL1),使用PCB中保存的页表基地址赋值给TTBR0_EL1。
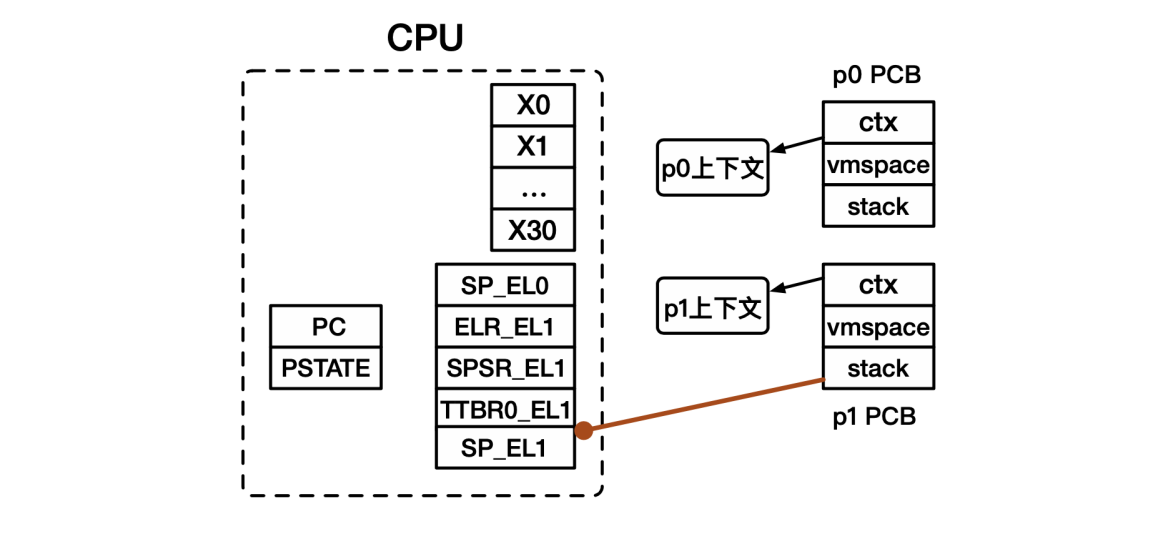
- 内核栈切换:设置内核中的栈寄存器SP_EL1,使用PCB中保存的内核栈顶地址赋值给SP_EL1。
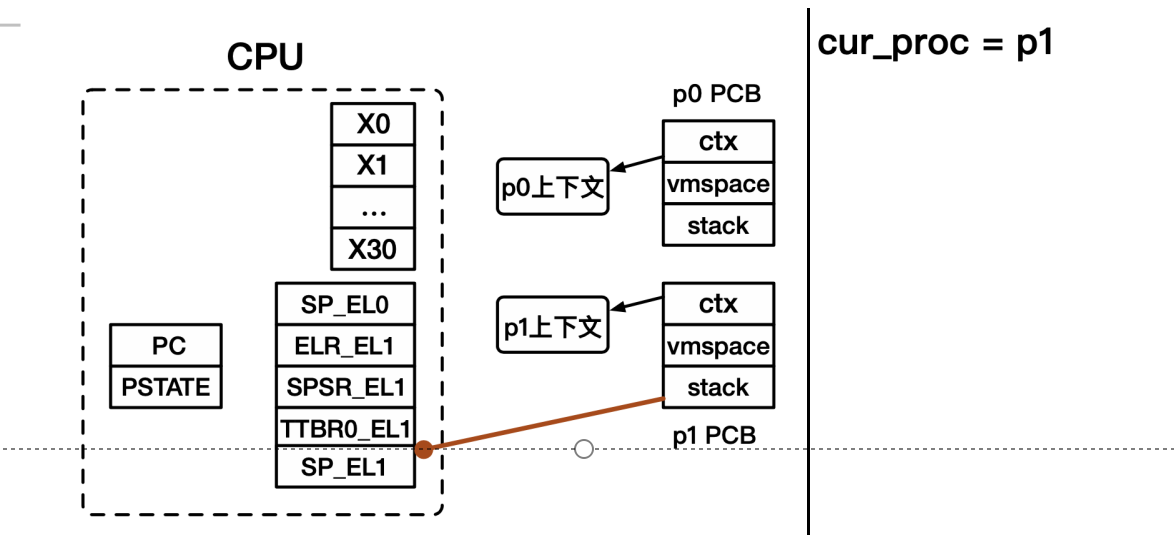
- 进程上下文切换:设置cur_proc为之后要执行的进程(p1),表明之后操作系统将以p1的身份运行。
- p1处理器上下文恢复:从处理器上下文中加载各寄存器的值,放入对应寄存器中。
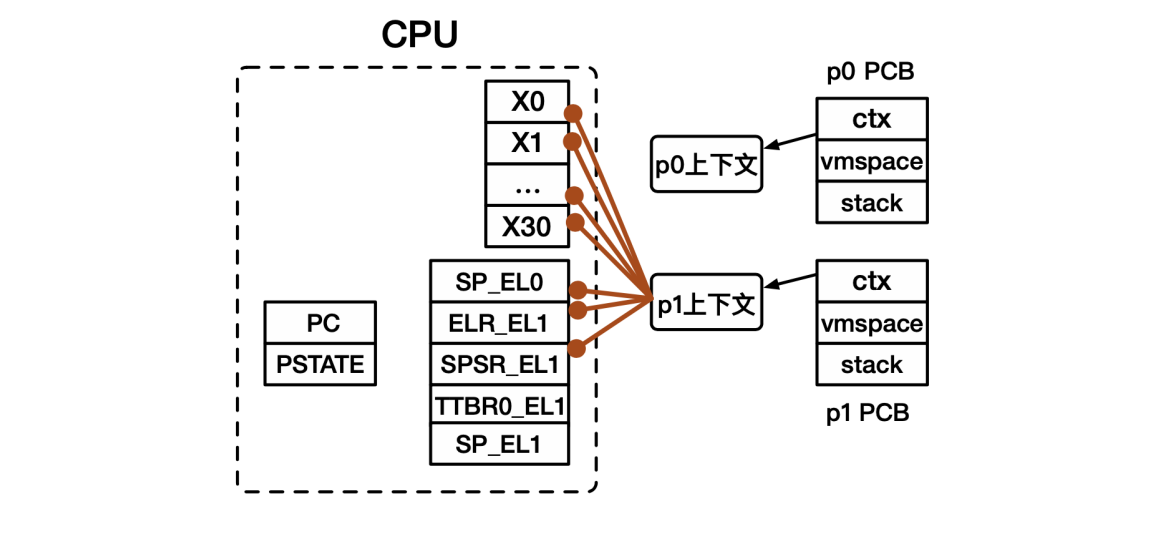
- p1处理器上下文恢复:由硬件自动恢复部分寄存器,将ELR_EL1和SPSR_EL1中的值自动保存到PC和PSTATE中。
线程
多核调度简单方法:进程数量一般远超过CPU核数,通过简单分配,使每个核至少分得一个进程。
存在局限:单一进程无法利用多核资源,一个进程同一时刻只能被调度到其中一个核上运行。
如果一个程序想同时利用多核,该怎么办呢?使用 FORK !
FORK局限:进程间隔离过强,共享数据困难,各进程拥有独立的地址空间,共享需以页为粒度,协调困难,需要复杂的通信机制(如管道)。而且进程管理开销较大,创建是地址空间复制,切换是页表切换。
线程介绍
线程只包含运行时的状态,静态部分由进程提供,包括了执行所需的最小状态(主要是寄存器和栈)。
一个进程可以包含多个线程,每个线程共享同一地址空间(方便数据共享和交互),允许进程内并行。
如何使用线程
- 常用库:POSIX threads(pthreads),包含约60个函数的标准接口,实现的功能与进程相关系统调用相似。
- 创建:pthread_create
- 回收:pthread_join
- 退出:pthread_exit
注意:一个线程执行系统调用,可能影响该进程的所有线程,如exit会使所有线程退出。
一个示例代码如下:
1 | |
主线程创建子线程后,两线程独立执行。若子线程先执行,则exit被调用,子线程直接被终止,如何避免?加入join操作!
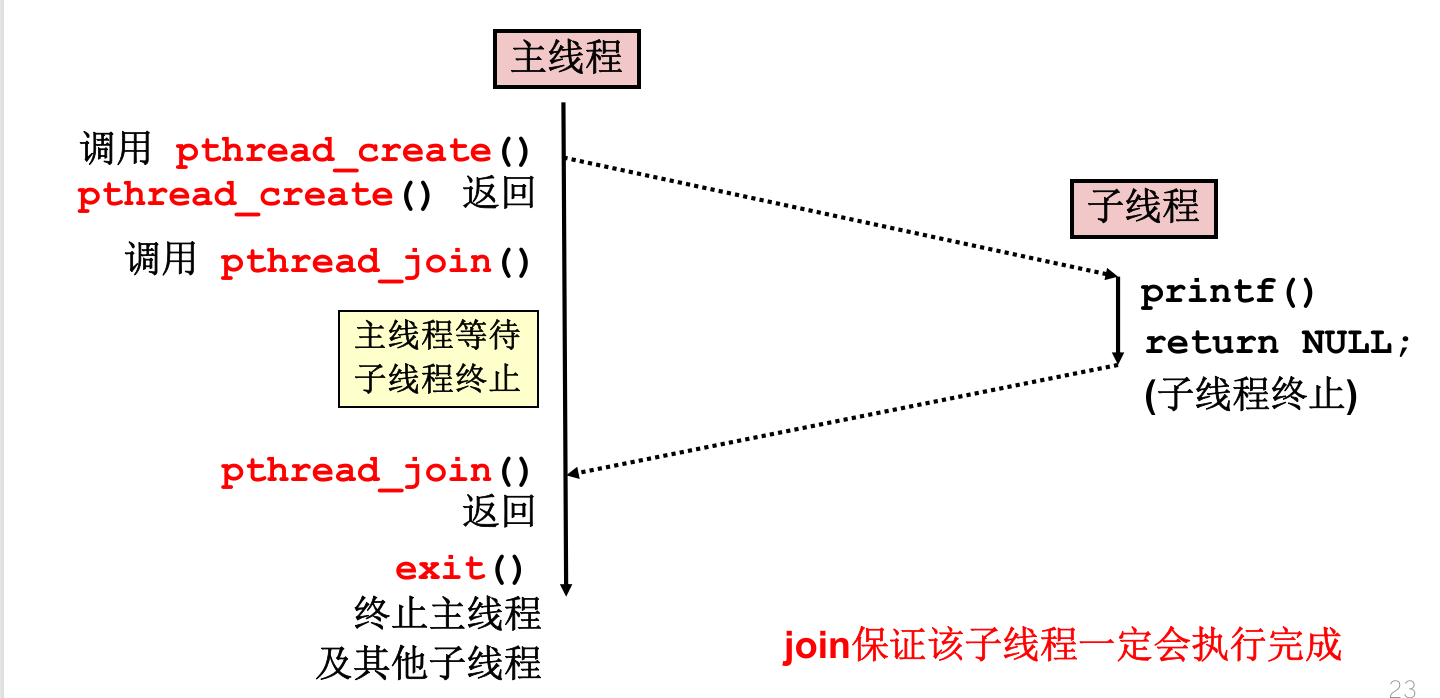
基于join的方法存在什么问题?需要主线程手动调用回收资源,若主线程未调用则可能出现资源溢出。
解决方案:加入detach操作。调用detach可使线程进入“分离”状态,分离线程不能被其他线程杀死或回收,退出时资源自动回收。
1 | |
如果detach和join一起使用会怎么样?会返回22,22代表illegal arguments,因为这个线程无法join。
detach代表线程完全独立了吗?没有。
1 | |
这样不会有任何输出,核心原因是主函数返回后隐式调用exit,强制终止所有线程。
解决方案:加入pthread_exit(见上面),只退出当前线程(参数为返回值)。
线程
多线程的进程
一个进程可以包含多个线程,一个进程的多线程可以在不同处理器上同时执行。调度的基本单元由进程变为了线程,每个线程都有自己的执行状态,切换的单位由进程变为了线程。
每个线程拥有自己的栈,内核中也有为线程准备的内核栈,其它区域共享(数据、代码、堆)。
用户态线程与内核态线程
根据线程是否受内核管理,可以将线程分为两类:
- 内核态线程:内核可见,受内核管理,由内核创建,线程相关信息存放在内核中;
- 用户态线程:内核不可见,不受内核直接管理,在应用态创建,线程相关信息主要存放在应用数据中。